
Get data from a webservice
Welcome back to my series of discovering Azure Data Factory. In this blog I’m going to get some data from a webservice and store it in parquet files. In my demo, I’m using the rebrickable API that provides a lot of data for Lego bricks. In my case, I wanted a substantial amount of data. To get all the data, I had to slow ADF down. Normally it has a request interval of 10 milliseconds. Cool but this free API will throttle you. So I had to back off to a request interval of 1000 milliseconds.
Pipeline and REST dataset
First step is create a new pipeline. That’s not the hardest part. What is more interesting is the how to get data from the webservice. When I look at this service, first thing is that I need to create an account to be able to get to the API. If you have an account, just create the API key. If you don’t create an account, verify your email address and get the key. Remember that you need to dig into the specific API documentation to find out the prerequisites for your API.
Now, to make a connection we need a dataset to function as a data source. Let’s create a REST API dataset.
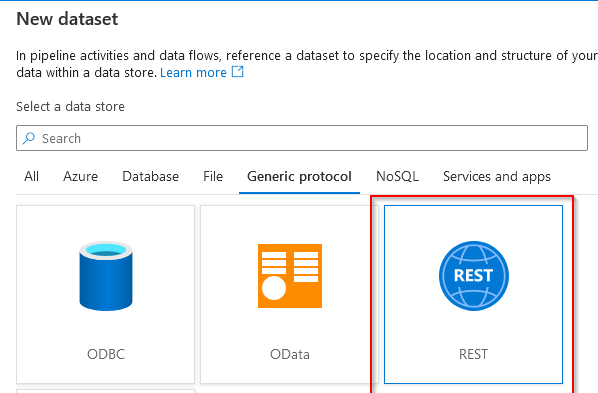
As we’ve seen in previous blogs, a dataset is nothing without a linked service. This service is something that you’ve either already created and can re-use, or you can create a new one. In my case, I’m going to create a new one.
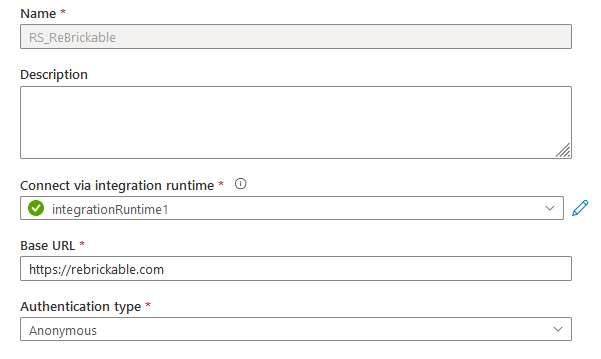
I’ve named my Linked Service RS_ReBrickable. I’m horrible at naming conventions, but this seemed right at the time as it’s a linked service for a Rest Service. The base URL is the fixed part of your API. The rest usually changes depending on the data you want to get from the API.

In my case, all I need to authenticate is a key and I have to include this in the header. I had some trouble getting this part right because the value for Authorization needed the entire part for the key. Not just the key value but ?key=342334324 (the numbers are made up of course).

At the parameters part of the lined service I have to provide GET and the key (again).
Pipeline and Copy data activity
Back to the pipeline, I’ve added a copy data activity. This will start to copy data from the API to parquet files.
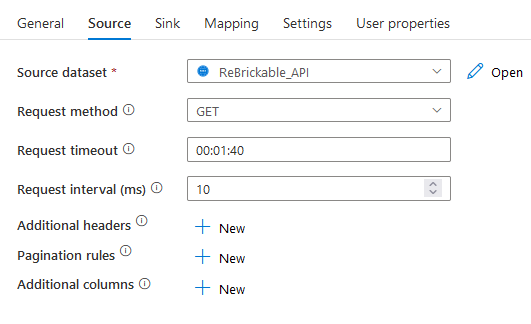
Source settings
In my source settings I can use my ReBrickable API. But, I have to add some info to make sure it will get data. Because the base URL will not return any info.

This is the part where you can add the relative URL part. This is the part that changes depending on your needs. In this case I’m going after the minifigs.
Sink settings

My sink is a Parquet destination. Same story as one of my previous blogs, let’s not wast bytes here.

First try
Ok, let’s keep this empty for now and see what happens.
It worked! But

Hmm, I got the header and that’s it. Not what I wanted.
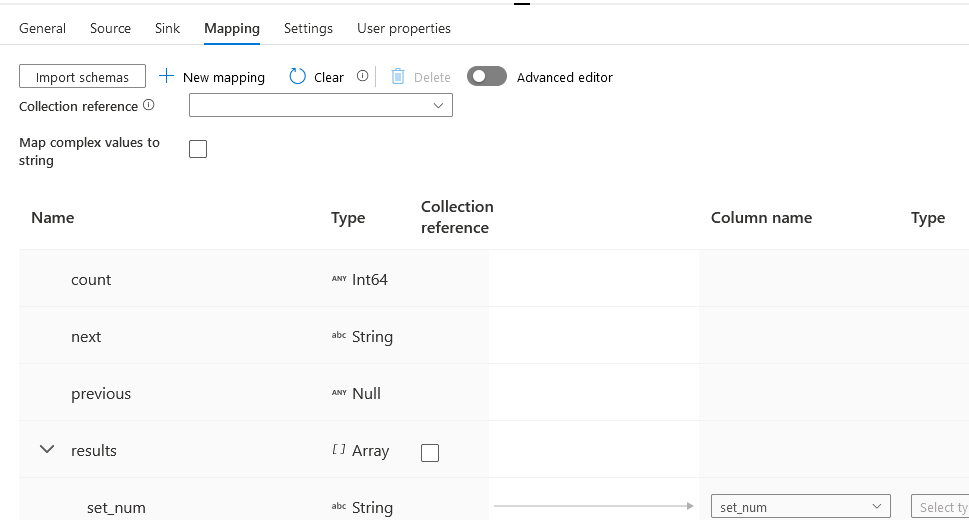
So,let’s import the schema to check out what that does. The schema is a parsing of the JSON that the API returns. It works quite nicely out of the box (with the advanced editor you can change all sorts of stuff). For now let’s keep it this way and see what happens.
Second try

Nice, more data, but still just one record. It seems that ADF can’t figure out what to do with the rest of the JSON.
There’s an option that you can use to determine the collection reference. This means that ADF can separate the JSON metadata from the actual payload. Very very cool stuff! Because I can just tell ADF that my payload is in the results array. Let’s go!
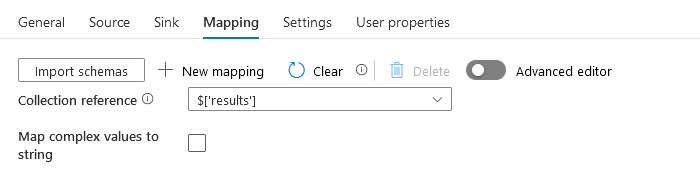
Third try, lucky?

Now look at this. One hunderd records. Wait, 100? That’s a weirdly rounded number to result from an API. It is possible but unexpected. In an earlier run, I saw a field named count with 11560, something that sounded closer to the truth.
Fourth try, pagination
This next part took me the best part of an hour to figure out. You have to tell ADF how to paginate through the dataset.

I had to change my source setting from the earlier /api stuff to the one shown above. In this case I’m telling the api I want to start with page 1 of the API result set and get 200 records. After that, give me the next page.
This means you have to find the ”next” part in the JSON. Every JSON is different in this regard. In my case the next value was in the base of the JSON and I could get to it with $.next. The value of $.next is an Absolute URI and immediately usable. To make sure ADF doesn’t keep on trying I’ve added an EndCondition as well with the const null. If there are no more pages to be found, the value in next is null. I’m not convinced this one is needed, but it doesn’t hurt either.



This is also the part, as mentioned at the start, where I needed to fool around with the request interval.
Finally
In this blog I tried to show you how to connect to a REST api. It’s a bit of a fiddle to get it to work and can’t see this working in a loop like I can reading data from a large number of tables from one database, though it’ll be a fun exercise to try out. I hope these steps help you out when you’re trying to accomplish a connection like this.
If you have any questions, suggestions or improvements, let me know in the comments! Feedback is appreciated.
Thanks for reading!
