A few days ago, I heard someone stating that Group By was much quicker than Distinct. Less disk impact, less memory etc.
So, I thought I’d find out if it’s true or not because I found it interesting. I always thought there was no difference. I tested a single small table and found no difference in speed, reads or execution plan. But that’s no real world example. Usually the tables contain a lot of data and are joined to other tables.
Setup
I’ve tried it out on my training environment with a fact table that contains about 97 million rows and two dimension tables containing way less rows. There are trusted foreign keys between the tables, the fact table has a clustered columnstore index on it.
Let’s create the query’s
SET statistics time, io on;
SELECT DISTINCT
FFD.ACTUAL_DEPARTURE_TIME,
FFD.SCHEDULED_ARRIVAL_TIME,
DA.AIRPORT_NAME
FROM fact.FLIGHTDATA FFD
INNER JOIN dim.AIRPORT DA ON FFD.ORIGIN_ID = DA.DIM_AIRPORT_ID
INNER JOIN dim.DATE DD ON FFD.DATEID = DD.DIMDATEID
WHERE DD.Year = 2005
AND DD.Month = 4
SELECT FFD.ACTUAL_DEPARTURE_TIME,
FFD.SCHEDULED_ARRIVAL_TIME,
DA.AIRPORT_NAME
FROM fact.FLIGHTDATA FFD
INNER JOIN dim.AIRPORT DA ON FFD.ORIGIN_ID = DA.DIM_AIRPORT_ID
INNER JOIN dim.DATE DD ON FFD.DATEID = DD.DIMDATEID
WHERE DD.Year = 2005
AND DD.Month = 4
GROUP BY FFD.ACTUAL_DEPARTURE_TIME,
FFD.SCHEDULED_ARRIVAL_TIME,
DA.AIRPORT_NAME
Execution plans
Let’s check out the execution plans first.
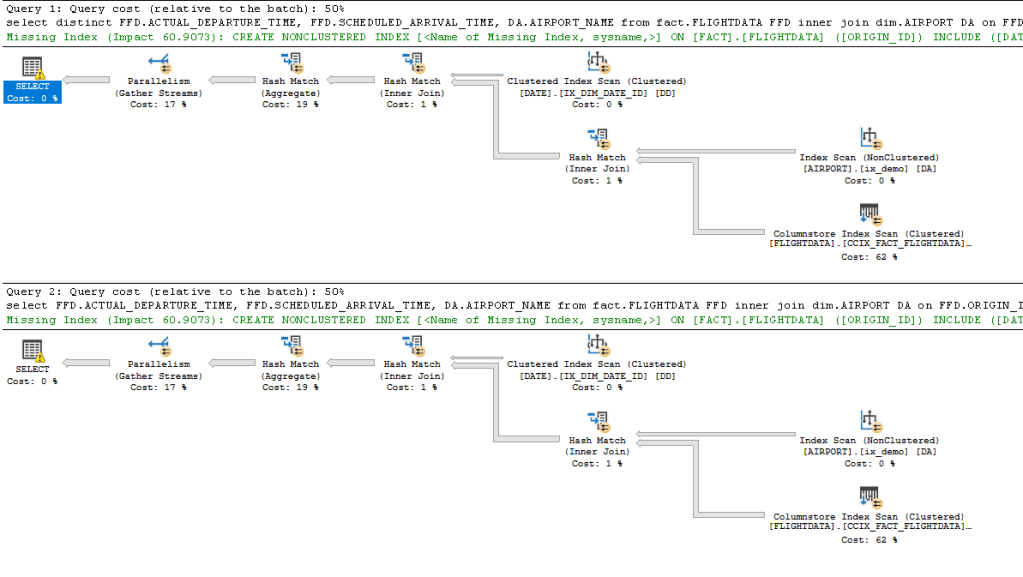
Not much of a difference visually. Both query’s have an estimated query cost of 34.7642.
Execution times
Let’s run them together and see the results.
Test A, running them together
(294444 rows affected)
Table 'FLIGHTDATA'. Scan count 4, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 46369, lob physical reads 0, lob read-ahead reads 0.
Table 'FLIGHTDATA'. Segment reads 27, segment skipped 68.
Table 'AIRPORT'. Scan count 5, logical reads 40, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'DATE'. Scan count 5, logical reads 205, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 859 ms, elapsed time = 1947 ms.
(294444 rows affected)
Table 'FLIGHTDATA'. Scan count 4, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 46375, lob physical reads 0, lob read-ahead reads 0.
Table 'FLIGHTDATA'. Segment reads 27, segment skipped 68.
Table 'AIRPORT'. Scan count 5, logical reads 40, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'DATE'. Scan count 5, logical reads 205, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 765 ms, elapsed time = 1901 ms.The distinct query took 1.9 seconds to complete (589 ms on the processor) and had all kinds of activity. Cool but let’s see how this holds up against the group by.
That one took less time on the CPU, finished a little bit quicker (about 40 ms) and had a fraction less reads on the fact table. But, the group by query had the slight advantage of possibly cached data from it’s predecessor. So, let’s free the procedure cache and try again.
Test B, running separately and clearing the caches
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
select distinct
FFD.ACTUAL_DEPARTURE_TIME,
FFD.SCHEDULED_ARRIVAL_TIME,
DA.AIRPORT_NAME
from fact.FLIGHTDATA FFD
inner join dim.AIRPORT DA on FFD.ORIGIN_ID = DA.DIM_AIRPORT_ID
inner join dim.DATE DD on FFD.DATEID = DD.DIMDATEID
where DD.Year = 2005
AND DD.Month = 4
(294444 rows affected)
Table 'FLIGHTDATA'. Scan count 4, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 67767, lob physical reads 8, lob read-ahead reads 117752.
Table 'FLIGHTDATA'. Segment reads 27, segment skipped 68.
Table 'AIRPORT'. Scan count 5, logical reads 40, physical reads 1, read-ahead reads 20, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'DATE'. Scan count 5, logical reads 205, physical reads 1, read-ahead reads 68, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1125 ms, elapsed time = 2421 ms.
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
select FFD.ACTUAL_DEPARTURE_TIME,
FFD.SCHEDULED_ARRIVAL_TIME,
DA.AIRPORT_NAME
from fact.FLIGHTDATA FFD
inner join dim.AIRPORT DA on FFD.ORIGIN_ID = DA.DIM_AIRPORT_ID
inner join dim.DATE DD on FFD.DATEID = DD.DIMDATEID
where DD.Year = 2005
AND DD.Month = 4
GROUP BY FFD.ACTUAL_DEPARTURE_TIME,
FFD.SCHEDULED_ARRIVAL_TIME,
DA.AIRPORT_NAME
(294444 rows affected)
Table 'FLIGHTDATA'. Scan count 4, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 67765, lob physical reads 8, lob read-ahead reads 117752.
Table 'FLIGHTDATA'. Segment reads 27, segment skipped 68.
Table 'AIRPORT'. Scan count 5, logical reads 40, physical reads 1, read-ahead reads 20, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'DATE'. Scan count 5, logical reads 205, physical reads 1, read-ahead reads 68, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1078 ms, elapsed time = 2943 ms.So with everything cleaned, the Group By spent a little less time on the processor but needed more time to fully complete. Now, there’s still SSMS that needs to process the results, so let’s stop printing the results in SSMS and try again. You can do this by right-clicking in your query window, go to query options and do the following:
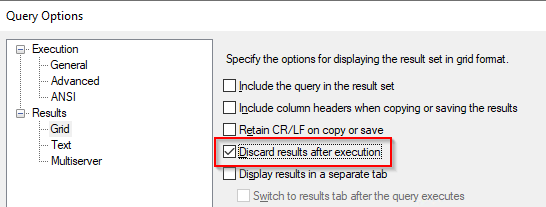
This option will stop the process as soon as the resultset has been gathered.
Test C, discarding the results after execution
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
select distinct
FFD.ACTUAL_DEPARTURE_TIME,
FFD.SCHEDULED_ARRIVAL_TIME,
DA.AIRPORT_NAME
from fact.FLIGHTDATA FFD
inner join dim.AIRPORT DA on FFD.ORIGIN_ID = DA.DIM_AIRPORT_ID
inner join dim.DATE DD on FFD.DATEID = DD.DIMDATEID
where DD.Year = 2005
AND DD.Month = 4
(294444 rows affected)
Table 'FLIGHTDATA'. Scan count 4, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 67767, lob physical reads 8, lob read-ahead reads 117752.
Table 'FLIGHTDATA'. Segment reads 27, segment skipped 68.
Table 'AIRPORT'. Scan count 5, logical reads 40, physical reads 1, read-ahead reads 20, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'DATE'. Scan count 5, logical reads 205, physical reads 1, read-ahead reads 68, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 906 ms, elapsed time = 877 ms.
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
select FFD.ACTUAL_DEPARTURE_TIME,
FFD.SCHEDULED_ARRIVAL_TIME,
DA.AIRPORT_NAME
from fact.FLIGHTDATA FFD
inner join dim.AIRPORT DA on FFD.ORIGIN_ID = DA.DIM_AIRPORT_ID
inner join dim.DATE DD on FFD.DATEID = DD.DIMDATEID
where DD.Year = 2005
AND DD.Month = 4
GROUP BY FFD.ACTUAL_DEPARTURE_TIME,
FFD.SCHEDULED_ARRIVAL_TIME,
DA.AIRPORT_NAME
(294444 rows affected)
Table 'FLIGHTDATA'. Scan count 4, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 67555, lob physical reads 8, lob read-ahead reads 117752.
Table 'FLIGHTDATA'. Segment reads 27, segment skipped 68.
Table 'AIRPORT'. Scan count 5, logical reads 40, physical reads 1, read-ahead reads 20, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'DATE'. Scan count 5, logical reads 205, physical reads 1, read-ahead reads 68, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 1032 ms, elapsed time = 867 ms.This time, the group by finished 10 ms faster but needed more CPU time.
Let’s get the times together.
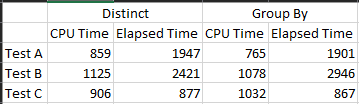
The A test was just running them together, test B was with empty caches and C was without printing the results. Yes there are differences, but minute. I can’t really say one is better than the other or one is quicker than the other, so I added a test that increased the number of rows.
Test 3, increasing the data volume by 10
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
select distinct
FFD.ACTUAL_DEPARTURE_TIME,
FFD.SCHEDULED_ARRIVAL_TIME,
DA.AIRPORT_NAME
from fact.FLIGHTDATA FFD
inner join dim.AIRPORT DA on FFD.ORIGIN_ID = DA.DIM_AIRPORT_ID
inner join dim.DATE DD on FFD.DATEID = DD.DIMDATEID
where DD.Year = 2005
(2251367 rows affected)
Table 'FLIGHTDATA'. Scan count 4, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 50569, lob physical reads 8, lob read-ahead reads 143963.
Table 'FLIGHTDATA'. Segment reads 33, segment skipped 62.
Table 'AIRPORT'. Scan count 5, logical reads 40, physical reads 1, read-ahead reads 20, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'DATE'. Scan count 5, logical reads 205, physical reads 1, read-ahead reads 68, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 6717 ms, elapsed time = 3103 ms.
DBCC FREEPROCCACHE;
DBCC DROPCLEANBUFFERS;
select FFD.ACTUAL_DEPARTURE_TIME,
FFD.SCHEDULED_ARRIVAL_TIME,
DA.AIRPORT_NAME
from fact.FLIGHTDATA FFD
inner join dim.AIRPORT DA on FFD.ORIGIN_ID = DA.DIM_AIRPORT_ID
inner join dim.DATE DD on FFD.DATEID = DD.DIMDATEID
where DD.Year = 2005
GROUP BY FFD.ACTUAL_DEPARTURE_TIME,
FFD.SCHEDULED_ARRIVAL_TIME,
DA.AIRPORT_NAME
(2251367 rows affected)
Table 'FLIGHTDATA'. Scan count 4, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 50577, lob physical reads 8, lob read-ahead reads 143963.
Table 'FLIGHTDATA'. Segment reads 33, segment skipped 62.
Table 'AIRPORT'. Scan count 5, logical reads 40, physical reads 1, read-ahead reads 20, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'DATE'. Scan count 5, logical reads 205, physical reads 1, read-ahead reads 68, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 6719 ms, elapsed time = 3068 ms.Again, there’s a difference but it’s still minute even though the data volume increased tenfold.
Concluding
So, is there a performance difference between distinct and group by. Strictly speaking, yes. But it’s not significant in this setup. Switching between distinct and group by won’t be the change that will get you over the finish line when you’re tuning. It will get you a little step closer. BUT! Remember that distinct applies to you entire result, when using group by you’re extending your options to group your data by. Make sure you don’t destroy the functional requirements of the query.
Thanks for reading!

One thought on “Distinct or Group By?”