
In my previous blogpost (Click here to read) I wrote about a query that just wouldn’t go parallel. This sparked some discussion and interest from a few people who were very kind and helpful with their suggestions and even deep dives into the query plans, execution statistics etc.
To make one thing very clear, this blog is 99% their work, only the typing and rephrasing is mine. This also means that mistakes are mine as I’m trying to join the different inputs together into a logical story. So let me introduce you to the heroes, order by first name ascending.
Bouke Bruinsma, Cláudio Silva, Daniel Hutmacher and Fredrik Boström. Each of these individuals can be found online on Twitter, Bluesky, LinkedIn or WordPress.
Analysis
After posting my blog, it didn’t take long for Daniel to reply. He gives a number of suggestions but the last one he gave, adding the query hint
OPTION(USE HINT(‘ENABLE_PARALLEL_PLAN_PREFERENCE’)) made a big difference.
This hint told SQL Server to skip the serial plan and go parallel on the 4 core VM with two cores per numa node (something Bouke replied to wondering, like me, what that is all about). So the query went parallel and the runtime dropped from 40-50 seconds to the expected 4-5. About the same time the old, on-premises server did with 8 cores split over 2 numa nodes.
Problem solved? Well, not really as this hint is an undocumented one, hence unsupported. It’s perfect for these testing scenarios, less so for production environments. And as some of you may know, any reporting system can come up with any query, so you need to add that hint to every single query. Good luck automating that. And yes, there’s a traceflag to accomplish the same result, but in that case, you’re doing it on a server level possibly decreasing the performance for everything else.
The most important thing this hint does is showing the parallel plan with the costs. And then, during fun exchanges with both Daniel and Cláudio, we found that the serial plan was marginally cheaper compared to the parallel plan.
194.643 for parallel
184.184 for serial
As I’m assuming the dot is the decimal separator, the serial plan is 10,5 cheaper than the parallel plan. Or in runtime, 10 times more expensive. So it seems that the SQL Server cost calculation isn’t much about runtime for the end user. When I checked the plan costs on the old, 8 cores in two numa nodes server, the numbers were different.
393.474 for parallel
440.586 for serial
So with more cores, the total cost doubled but parallel became cheaper than serial, making SQL Server choose to go parallel. And by that, saving the end user a lot of time. But how do these numbers compare with the changed server in Azure where there are more cores?
405.643 for parallel
449.185 for serial
The parallel plan is more expensive, but cheaper than the serial plan, even though the numbers are higher compared to the on-premises environment. That will possibly have to do with differences in numbers of rows, statistics etc. At least not something worth digging into.
Then Cláudio replied after doing some analysis. He found a blog by Paul White, where Paul explains that when SQL Server costs a parallel plan, it generally reduces the CPU cost for a parallel iterator by a factor equal to the expected runtime degree of paralellism.
So let’s see what the differences are. For instance a Hash Match operator. It has a CPU cost.
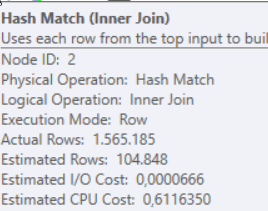
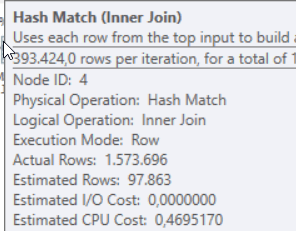
The quick plan has a lower estimated CPU cost, something that can be traced with all the operators that are registering CPU usage. The total query CPU cost sums all these CPU costs and then adds the IO cost to it to come up with a total cost, memory doesn’t seem to be included into the cost calculation.
One thing I was wondering about was the estimated degree of parallelism. No matter what queryplan I checked in these environments, the amount was matching the number of cores in the Numa node. This lead me to the conclusion that SQL Server estimates this degree on the amount of cores in the Numa node.
The post by Paul White states otherwise; the degree of paralellism estimate is limited to the number of logical processors that SQL Server sees, divided by two. So my laptop with 8 cores should show an estimate of 4 cores if Paul is correct or 8 cores if my assumption is correct.
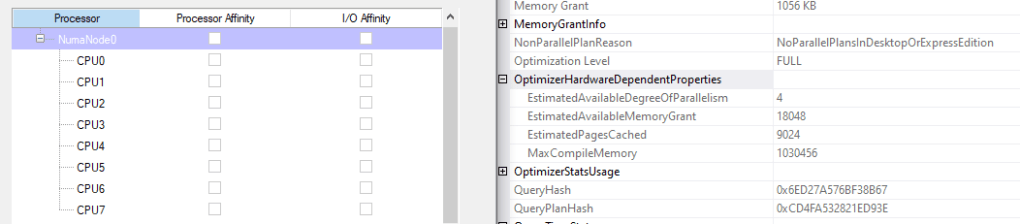
Of course, I’m wrong and Paul is right; my 8 core laptop leads to an EstimatedAvailableDegreeOfParallelism of 4. My laptop has multiple instances running, for this quick check I chose to use Express Edition. I didn’t know Express couldn’t create parallel plans by the way.
Cláudio finishes his analysis by stating that SQL Server did take the two core parallelism into account but apparently this was more expensive than the serial plan and therefore decided to go serial.
And now that we know?
Now that we have more knowledge on why this happens, is there anything we can do? As the code is generated by the reporting tool, rewriting the query isn’t really an option.
I’ve asked Hugo Kornelis and as far as he knows, the exact science between the cost calculation isn’t available for us mere mortals. It has something to do with a famous pc but other than that it’s a mystery.
I’m not ready to unleash undocumented traceflags on a customer production system and hope for the best.
I did however find some official Microsoft documentation on best practices for Azure VM’s running SQL Server. The SKU’s mentioned here are different to the ones used by the customer and are worth exploring. In general I try and deploy the most recent versions of VM’s when I can as the hardware is usually newer and pricing can be better as well.
https://learn.microsoft.com/en-us/azure/azure-sql/virtual-machines/windows/performance-guidelines-best-practices-checklist?view=azuresql
Fredrik Boström suggested that index seeks instead of scans might help in reducing cost in a serial plan and therefore help in triggering the parallel plan instead of a serial plan. I did see missing index hints in a plan that ran parallel. I can’t show that for obvious reasons but it might just be the case that this will be the final step in this mystery. Followed by the joy of analyzing N amount of query’s and checking if indexes help. Or just scale the VM up with more cores. It’s the customers choice which of these two fits better in their budget.
Learnings
- The sqlfamily is awesome (ok, I already knew that but it can’t be overstated)
- If a plan keeps going serial, use a query hint to make it go parallel and check the differences in cost
- Bookmark the post by Paul White for reference
- Lower cost on the SQL Server side doesn’t mean faster query results for the end user
- SQL Server Express doesn’t create parallel plans
- The estimated degree of parallelism is the amount of cores divided by two. This number is used to calculate the cost of the CPU cost of the operator
- The total query cost is a summation of both CPU and IO. Memory isn’t included in the cost
- Sometimes is can be cheaper to just add cores to the virtual machine instead of reworking every single query
These were my main learnings probably among some others. It was really fun to dig deeper into these issues. But it would have been impossible without the people mentioned at the top of the blog. They are the true heroes of this story.
Thanks for reading and if you have anything to add or seen a mistake, please let me know in the comments!

One thought on “Why won’t you go parallel, part 2”