
This blog is aimed at this weird wait type you shouldn’t be familiar with. But if you come across this type, I hope this blog will save you some time with reasons why it’s showing up and what to do about it. In any case, make sure to contact Microsoft. Because there is something wrong with your database.
Context
In august 2020 we started a project for a customer where we transferred their datawarehouse from an on-premises environment to Azure. At the start we created a number of serverless databases that would pause when not used.
After a few iterations we found that the only database at that time that produced enough power to sustain the ETL loads was the Hyperscale edition. We activated this edition around the end of september. After you make that decision there’s no way back. Once you go Hyperscale there’s no downscale. In the meantime we changed from serverless to general purpose to business critical and back. So almost all possible variations were used for this database to find out which one would suit our needs.
First symptoms
The first symptoms that something was wrong came when the vulnarability assessment timed out. If you go into the Azure Portal you can check out the security settings and start a scan. That scan started failing because of a time-out. Mitigated issues wouldn’t show up, even after the scheduled runs showed as being successfull. It didn’t matter if we tried to run it from a VM with PowerShell, from the Azure CLI or from the portal itself. Time-outs kept turning up.
We opened a case with Microsoft and after some investigation the conclusion was that over 100.000 columns in a database was a bit much for the vulnarability assessment, mainly for the column classification. This function is due to be deprecated in a few months from now and that was the end of that. Not really satisfactory I have to say but the case was closed.
After that we tried to alter the log retention period. Defaulted as six days, we wanted to go to ninety days. But this process timed-out as well. Weird because it’s just metadata and shouldn’t do this. Again a case was opened with Microsoft but little progress there as well
The performance hit
And then all of a sudden performance went. Processes that used to take about 15 minutes all of a sudden needed more than an hour. The 15 minutes was already considered slow. But with a total schedule that started running ages instead of hours, we were in trouble.
So, we contacted Microsoft, again. But this time we had very clear culprit. Because of the wonderfull book by Enrico van der Laar, I could check the history of my wait statistics.

Above you can see the regular waits for our loading process. There’s processor load, network etc. I took the top 5 from the start of the process.
When things went wrong, this is what showed up:
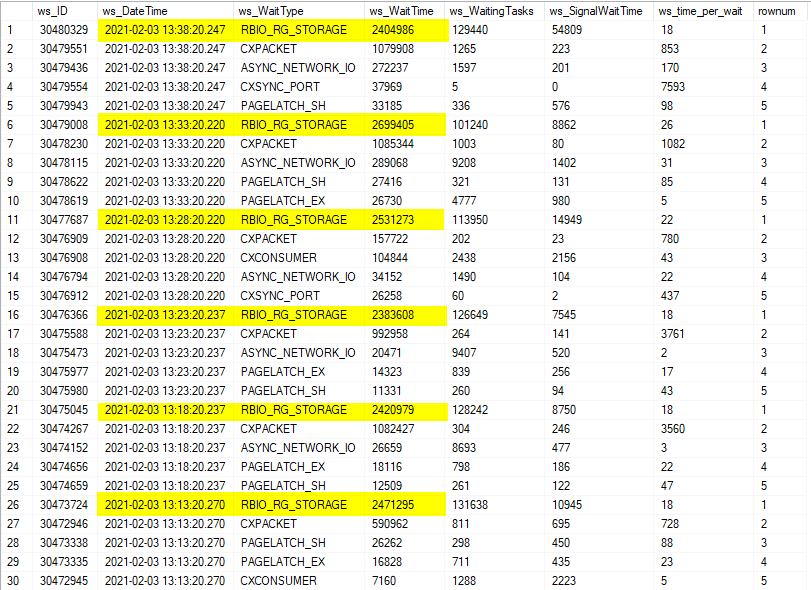
This single wait made sure our complete environment went dead in the water. Everything halted. To get some context, Microsoft has some documentation on this wait:
Occurs when a Hyperscale database primary compute node log generation rate is being throttled due to delayed log consumption at the page server(s).
Well, that’s not really helping, because that’s about everything they tell you about it. There is a diagram of how the Hyperscale environment works:

Solution
This technical stuff isn’t visible to us as regular users, so I had a number of interactions with Microsoft support to check out what was happening here. Because the diagram shows multiple Page Servers, my assumption was that one or more page servers in our database was broken. But I can’t test that.
And for this moment this seems kind of true.
What happened: When we tried out a number of tiers for our database before moving to the Hyperscale database, we set some kind of background flag that changes the creation of the Hyperscale database. It doesn’t give you (a number of) 128 GB Page Servers but one of 1 TB.
One page server with a size of 1 TB, for a database that’s somewhere around 400 GB in size.
The Microsoft advice was to create a new database and transfer all the data from the old one to the new one. That meant reading 400 GB of data from a database that’s not performing at all. As this was a production issue, we chose not to do that but to restore a back-up. Because what else do you have those for?
The first few hours after restoring the database it was blazing fast. After that it sank back somewhat with regard to speed. But the vulneratbility assessment succeeds again and log retention is set to 90 days.
This behaviour is qualified as a bug and is set to get fixed within 6 months or so. That means it shouldn’t happen after august 2021. I can’t check that for you. But if you come across this wait type and you lose performance?
If you want to prevent this from happening, start with a clean Hyperscale database.
It still feels a bit weird and right now, i’m not completely convinced of the Hyperscale performance. It’s quick but not blazing fast. But maybe we need to do some more tuning.
Anyway, thanks for reading!

One thought on “RBIO_RG_STORAGE wait on Azure Hyperscale database”