
I got a question some time ago about a query not performing. There seemed to be an issue with SQL not using the best possible index. Now this issue is already vague and it took me some time to understand what was happening but with a simple demo I could replicate some of the issues.
Set the stage
The demoscript will create two tables. One with some nonsense data and a computed column resulting in a varbinary column, the other one with comparable nonsense data and a fixed column with the varbinary data. The query will do some joining on the tables to get the rows that don’t exist in the other table. This code is taken from a third-party application.
* Create the main table */
create table ByteMyHash
(
id int identity(1,1) primary key,
col0 varchar(100) null,
col1 varchar(50) null,
[SCD Surrogate Hash Key] AS (CONVERT([varbinary](20),hashbytes('SHA1',
coalesce(CONVERT([varbinary](16),[Col0]),0x00)+0x0001)+
coalesce(CONVERT([varbinary](12),[Col1]),0x00))+0x0002) PERSISTED NOT NULL
)
/* Add data */
insert into ByteMyHash (col0, col1)
values('fdsf','sdfsdfsfsdf'),
('dfsgert','sdfdsfdsfsadfasdf'),
('sdfdfewrvcvxcvwertdfsdfvg','dsfsdaferxccvser')
go 50
insert into ByteMyHash (col0, col1)
values('fdf','sdfsdfdf'),
('dfsgrt','sdfdsfdsfasdf'),
('sdfdfewrxcvwertdfsdfvg','dsfsdafervser')
go 50
/* Add indexes */
create index cols on ByteMyHash
(
col0, col1
)
create index col1 on ByteMyHash
(
col1
)
create index col0 on ByteMyHash
(
col0
)
create index allcol on ByteMyHash
(
col1, col0, [SCD Surrogate Hash Key]
)
/* Fill the second table with distinct data from the first table */
select distinct col0, col1, [SCD Surrogate Hash Key]
into HashmyByte
from ByteMyHash
/* Add an index on the second table */
create index ix_all on HashmyByte (col0, col1, [SCD Surrogate Hash Key])
Now, we’ve set the stage, next up, the first try of the query
Get some data!
/* Show the IO en compute times */
Set statistics Time, IO on
/* Run this query with execution plan with runtime statistics */
/*traceflag to show "hidden" objects in the queryplan */
DBCC traceon(9130)
SELECT
*
FROM HashmyByte T
WHERE
NOT EXISTS
(
SELECT TOP 1 1
FROM ByteMyHash V
WHERE
V.[SCD Surrogate Hash Key] = T.[SCD Surrogate Hash Key]
)
option(recompile)
When I’m running this query, this is the result:
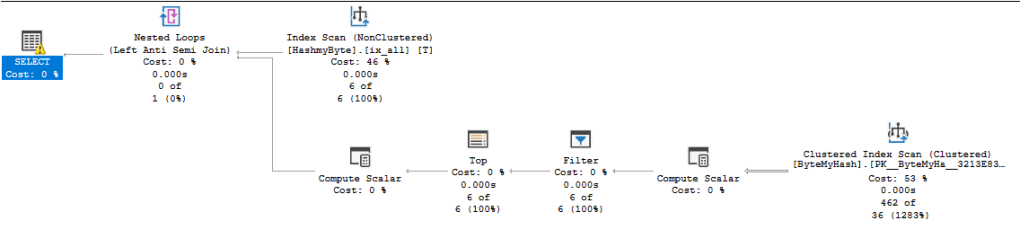
One of the things that is weird are the rowcounts. The ByteMyHash table contains 300 rows. But SQL seems to think it contains 462. The HashMyByte table contains 6 rows, for each row in this table, it needs to check the rows in the ByteMyHash table and get the fitting rows back. In a way, 6×6 = 36, this makes some sense. But the rest, right now, doesn’t. Update the statistics on this table? Did that, no effect whatsoever.
There’s a yellow warning on the select statement that tells me this:

This warning gives some clue. SQL isn’t all that happy with the conversion of a varchar to a varbinary. Let’s see what happens if we give the optimizer a helping hand, add a column with just the varbinary data in it instead of the computed column and check it again.
Change the stage, add a column
/* Add a fixed column that contains the values from the computed column */
alter table ByteMyHash
add HashCol varbinary(22) null
/* Update the data */
update ByteMyHash
set HashCol = [SCD Surrogate Hash Key]
/* Check the results */
select *
from ByteMyHash
Now, let’s change the query to join on the better column and all should be well, right?
SELECT
*
FROM HashmyByte T
WHERE
NOT EXISTS
(
SELECT TOP 1 1
FROM ByteMyHash V
WHERE
V.HashCol = T.[SCD Surrogate Hash Key]
)
option(recompile)

Index it!
And off course this doesn’t work, because silly me forgot to add an index!
/* add an index on the new column */
create index turbo on ByteMyHash (HashCol)
Let’s see what happens next

Now the plan is way more compact and the Index Seek is hitting just 6 rows.
At this point, my little poor table is littered with indexes and that’s not good. Clean up indexes that are useless, overlapping with other indexes, just duplicates or otherwise unnecessary.
Before you go, the dataset was really small. So I’m going to do the same stuff again, but with a lot more data to show the impact of the computed column.
Enlarge the dataset
The table now contains 150.000 records. Still not much but we might be able to spot differences more easily.


With the more fitting index, reads have decreased as has the elapsed time. Not by much but that’s got more to do with this demo I think.
Conclusion?
To round this one off, I think that computed columns have their use, but can, in some cases, become a burden. This might be one of those cases. In the real life scenario this demo is based on, the performance hits were much larger and SQL consistently chose the wrong indexes to support the query.
Finally, I’m still learning (and will be for the rest of my professional life) how to analyse these issues. If you think it’s all wrong, parts are wrong or you just disagree, please let me know. I love a conversation, discussion or meeting where everyone can learn and grow. In the end, I don’t mind being wrong. I mind being wrong and not being told (or only behind my back).
Disclaimer. This demo contains the use of an undocumented trace flag and has been run on a local machine without any production data. I would strongly advise you not to replicate these steps on your production environment to prevent issues or undocumented behaviour. The demo has been run on a Windows 10 laptop (6 cores, 40 GB Ram and 2 nvme disks) with a SQL Server 2019 Developers Edition installed.
Thanks for reading!

One thought on “Computed columns acting weird”