
Welcome to my blog series on Azure SQL DB performance. In this blog I’ll write about my findings with the Azure SQL DB Managed Instance tier.
Click here for information about the set-up
Click here for the scripts I’ve used
Intro
So far, the blogs were about the really SaaS databases; the database is deployed and you don’t have think about it anymore. This ease of use comes at a ‘price’. You’ve got no control whatsoever on files, you’ve lost the SQL Agent and a number of other features. The managed instance is a bit different. When I was testing you could see the TempDB files but not change them, since then a few changes have been made to this tier where you’re able to change settings and, Niko Neugebauer told the data community on twitter, there are more changes coming. With the managed instance, you get the agent back and you can run cross database query’s again. So you can safely say the managed instance is a hybrid between your trusty on-premises server and the fully managed Azure SQL database.
There are a few things to keep in mind, I haven’t tested the 40 and 80 cores Managed Instance nor the business critical one. The latter has a standard, premium and memory optimized premium series. This has to do with budget. Because the managed instance takes a long time to deploy (my record being 10 hours before deployment completed) and changing database SKU’s takes a lot of time as well (again waiting for an hour isn’t uncommon), planning tests is critical. And in the time it takes to change SKU, you are paying. Another thing to keep in mind is that the good people of Azure are constantly improving the database, adding new features and making the overall product better. This means or might mean that some of my findings from last summer are obsolete.
Limits
The managed instance tier starts at 4 cores as a minimum and goes up to 80. Storage starts at 2 TB and can go up to 16 TB. This the maximum per instance, not per database.
The log rate is 3 MB per second per core with a maximum of 120 MB/s. This translates as 12 MB per second in the 4 core tier and 120 MB per second for 40 cores and up. The data and log IOPS are between 500 en 7500 per file, where you need to increase the file size to get more IOPS. The IOPS roughly translate to 2MB per second up to 29 MB per second. The fun begins as the data throughput is mentioned as well, being 100 to 250 MB per second per file where you need to increase file size to get better IO performance.
The data limitations are core-bound as well, more cores offers more storage and with more storage you get better performance. For me, this translates to having more performance equals more resources and a risk of overprovisioning.
Resources provided
I’ve deployed most of the standard options and got the following results:
If you’re looking at these numbers, there are quite a few weird things happening.
SKU | Memory | CPU Cores | Max workers | Schedulers | Scheduler total count |
| MI_GP_Gen5_4 | 15 | 4 | 2 | 4 | 82 |
| MI_GP_Gen5_8 | 33 | 8 | 4 | 8 | 84 |
| MI_GP_Gen5_16 | 69 | 16 | 8 | 16 | 92 |
| MI_GP_Gen5_24 | 105 | 24 | 12 | 24 | 36 |
| MI_GP_Gen5_32 | 145 | 32 | 16 | 32 | 108 |
| MI_GP_Gen5_40 | 184 | 40 | 20 | 40 | 52 |
Memory has a quite stable rate with which it increases. That gives some form of predictability but as a DBA, I like lots of memory.
The cores have a nice alignment with what is deployed according to your chosen SKU. The workers on the other hand is only half the number of cores. The number of schedulers, that in my opinion determines the amount of work the database can do, has a much more balanced growth and are in line with SKU description. Every scheduler is ‘bound’ to a CPU core. It should be that the number of schedulers represents the number of cores. Yes, there are hidden schedulers but these should be hidden from the used view as well.
Running query’s
We’re not using a database to sit around idle; we need to insert, read, delete and update data (in whatever order you fancy). When you look into the code post, you’ll find the scripts I’ve used to do just that. Insert a million rows, try and read a lot of stuff, delete 300.000 records and update 300.000. The reads, updates and deletes are randomized. Because of the large number, I think the results are useable and we can compare them between tiers and SKU’s.
Insert 1 million records
I’ve inserted the records on all SKU’s within this tier. With 4 cores, this took a little over 37 minutes. You can see some variation in time but there’s not a real significant increase in time; inserting data keeps taking a long time.

Wait types I’ve seen the most:
The shared page io latch wait took 42 percent of the time. The wait indicates that it takes time to finish reading a page from disk. Combined with 21 percent of the time waiting on the log writing, the disk(s) were suffering. Exclusive access to data pages and shared access to pages in memory adds two times 11 percent tot the total wait time. 64 percent in total is spent on waiting for access to data pages. That’s a lot. From another perspective, about 74 percent is spent waiting on disks. Only the latch wait isn’t directly related to disk. When we look back at the limitations, the more disk you provision, the faster it gets. As I provisioned small from a budget point of view, I suffered from the slow speeds.
Let’s see what happens on the disks latency-wise.

The graph is seriously skewed, because if the enormous write latency, you can’s see the read latency anymore. This varied between 14 and 80 ms, averaging at 51 ms. The write latency varied between 32 and 3932 ms, averaging at 1752 ms. I think I can safely say that creating a small database is very good for high latency.
Select data
After inserting data, it was time to select some. The script that I’ve used is intentionally horrible to make the worst of the performance. The 4 core DB took 7 hours and 12 minutes to complete. The 32 core SKU finished in just over 49 minutes. Compared to the inserts, this looks much more like it! Like other tiers, it’s a bit of an asymptote. The increase of speed slows down and at some point more hardware won’t get you anywhere quicker.

The wait types I’ve seen the most:
The main wait had to do with query’s having to leave the processor. Remember the horrible query I wrote? That’s why it takes 30 percent of the time. Second is parallelism. I didn’t do anything with max dop, query tuning or statistics refreshing, so this is expected but taking 40 percent of wait time an easy target for tuning. Latching was responsible for 19 percent of the time. Updating the Azure portal took 2 percent of the time just like the shared latch.
Let’s take a look at the latency
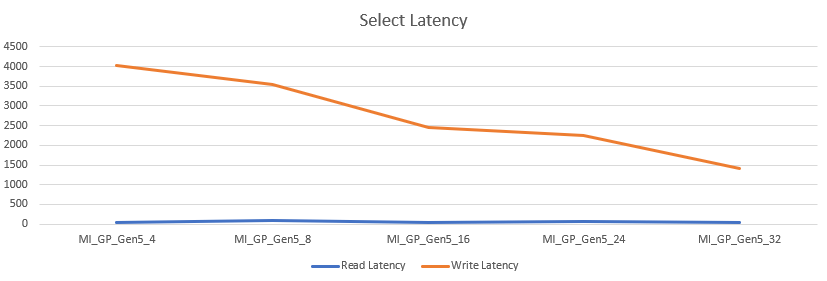
The read latency stayed relatively low between 36 and 80 ms, averaging at 52 ms. The write latency remained very high between 1409 and 4023 ms, averaging at 2735 ms. I couldn’t figure out why the write latency stayed this high, the write operations are supposed to go to TempDB. The positive is the read latency that, even though the numbers are high, didn’t kill the overall performance of the query’s. 49 minutes at 32 cores is faster compared to the 1 hour and seven minutes that the Business Critical tier with 32 cores needed to complete.
Delete data
After selecting data I decided I had enough of the large amount and had to trim some of. So I deleted 300.000 records. This process is quick all over the board, except for the 4 core machine that needed two minutes. The 8 core machine quartered the time, after that the duration swung around the 20 seconds mark.

The wait types:
This is the first tier where the scheduler yield makes a prime appearance during the deletes. It seems a single delete takes more than 4 milliseconds. At 41 percent of the time, this wait immediately makes an entrance. Parallelism comes in at second and third place combined 42 percent. Exclusive access to pages from disk is the last relevant one at almost 5 percent.
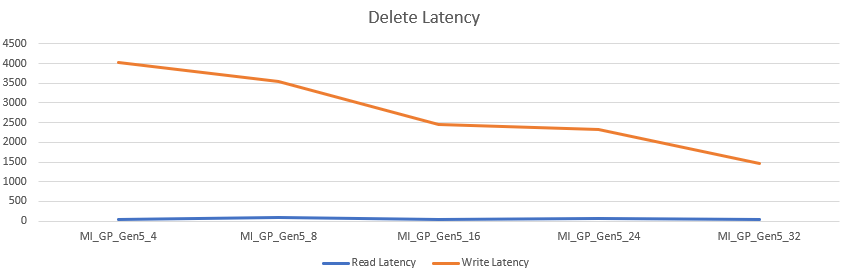
Just like the select latency, more cores offers more speed, even though the disk sizing didn’t change. The read latency sat between 36 and 78 ms, averaging at 52 ms. The write latency sat between 1469 and 4039 ms, averaging at 2767 ms.
Update data
The last job I let rip on the database was an update task. I ran a script to update 300.000 records. The 4 core tier took 44 seconds, the 32 core tier took 19. The behavior is quite different from the delete. Where deletes started slow and quickly reached the best performance, the updates started quicker but increased in steps.

Let’s take a final look at the waits
Waiting for reading pages from disk took (combined) 58 percent of the time. Exclusive access to data pages in memory took 15 percent, closely followed by log writes at 13 percent. The portal took 8 percent and finally the logbuffer came in with a little over 1 percent. This last one has to do with freeing up the log buffer in the log cache.
Let’s see if the disk latency is comparable with the latency seen at the deletes.

The latency is almost identical to the updates. So no wasted words here.
Pricing
The pricing shows an even line over the different SKU’s. Every core will set you back, in this case, 195,21. Prices have changed since my measurements but the concept will be the same.
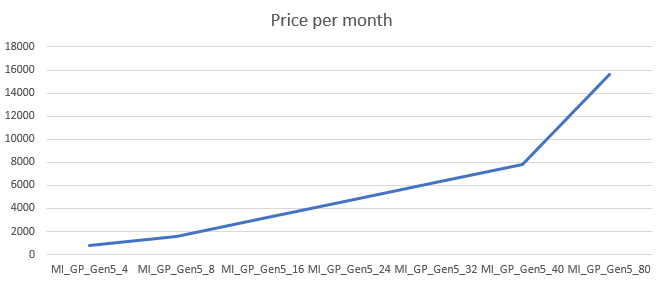
More performance will cost more and you’ll have to decide if this tier and it’s SKU is worth the cost. To keep this under control I’d advise you to use the cost center and it’s alerts. Not only the actual costs, you can create cost alerts on predicted costs as well to prevent surprises. We’ve all been there.
An extra warning as from October. As energy prices rise, so do the prices of Azure resources. I’ve seen increases in price for various resources including databases and VM’s. Both in pay as you go and in reserved instances.
Finally
The Managed Instance tier is a special one. It has a lot of potential with compared to the other tiers when we look at the options. Things like the SQL Agent and control over your files are options DBA’s like to have. As updates and backups are still handled by Azure, you get the goodies without the boring, time consuming stuff.
The major drawback for me is that you need quite a lot of space to get the disk performance. It’s a bit hidden in the documentation but you need to be aware of this. Another drawback, though a lesser one, is the time it takes to deploy and scale. Now during the writing of this blog, I read that faster deployment are being released in preview, but it’s still nowhere near the single minutes that the other tiers offer. Same goes for scaling up or down. These processes take time. If you want to save money by scaling down when databases are used less and scale up when databases are used more, I’d suggest looking at another tier. If you deploy once and never touch the SKU again, by all means see if this one fits your use case.
Thank you so much for reading.
Next time, the full recap.

One thought on “Azure SQL Database Performance comparison part 9 of 9: Managed Instance”