
It’s been some time since my last post on Azure Data Factory, but I had some fun this week and wanted to share the learnings.
This blog will cover how I read files from an sFTP site, use the copy activity if the file hasn’t been processed yet and write some data into a table for future use.
What to do
Now before I dig into the techy stuff, let’s take a step back and look at the problem. The issue I want to solve is that the sFTP server hosts a number of files. These files can be here one day and gone the next. But they can stay there for some time (months probably). Because processing data in data flows costs money, I want to read and process each file just once and then not do it again. One option would be to read the file, process the contents and move it to a different directory. But that only works when you have more than just reading permissions. In most cases with vendors, you don’t. All I can do is read the files. So my strategy is to filter out the files I’ve already processed. This assumes that files are static, check with your vendor if they only use static files or that they update files as well.
In a simple flowchart, it looks something like this.
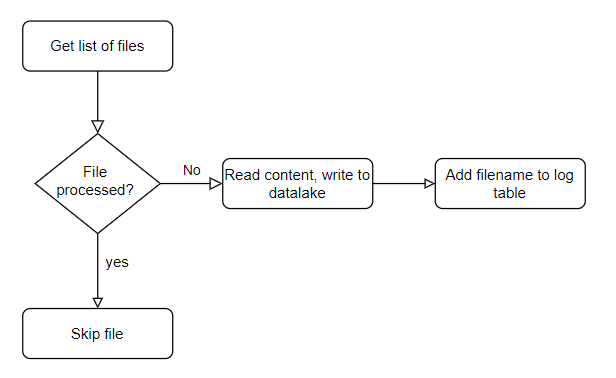
Strategy
My pipeline will need to get a list of the files on the sFTP server. Then I want to compare those files with the list of files I’ve already processed and if a file is new, then the data can be ingested into my data lake. If the file succeeds, I want an entry in my database when the file was processed and that it was successful. If it fails, I still want the entry but then with a failed state and if possible with something like an error message.
Spoiler alert, the error message is quite hard to retrieve, it’s easier to look it up in the run history.
List the files
So the first step is to create a list of files. To do this, I log on to the sFTP service and get the list of files there. To do this, I’m using a GetMetadata object. Within this object, I’m asking for the child items.
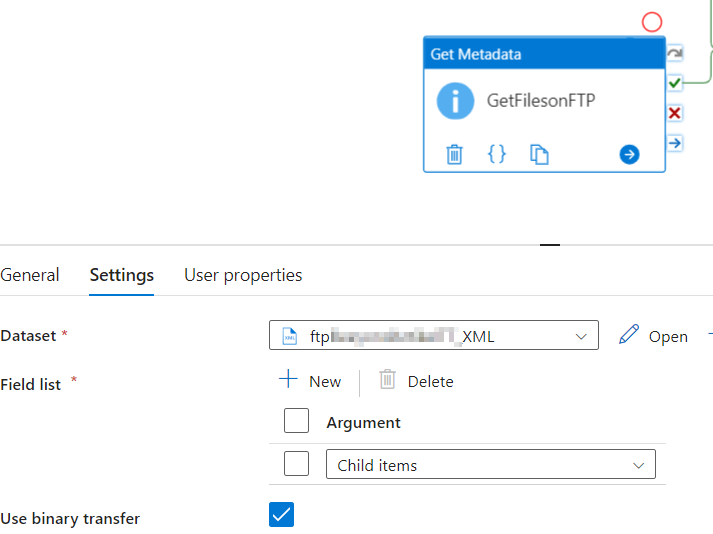
Getting and writing the file data
Now, to get the data of the files that have or haven’t been processed, I need to have a table with the following structure.
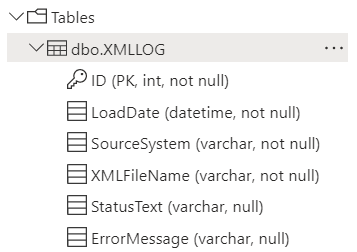
With this table created, I can use a sql script to get all the filenames. The other columns are mostly metadata for support and other usage. As it’s not (yet) possible to write out the error message in a simple manner, this column can be ignored for now.

If you look at the output of this select, you’ll see a string. But getting data from a string is a messy business. So, to get the data in the correct ‘format’, I’m dumping the list of filenames in an Array variable. Comparing rows against an array goes quite quickly.
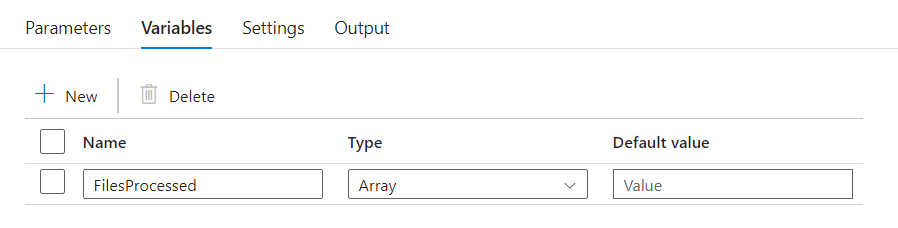
Iterations and conditionals
To get to the copy activity, we need to determine if a file has been processed or not. To determine if a file has been processed, I’m doing a select on the table where I’m keeping track of all the processed files. Logically writing, I’m getting all the filenames, check them against the list of processed files and if they’ve been processed, skip them. If not, get the data out and write the contents to the data lake files.
So for each file:
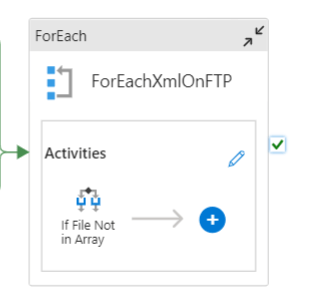
The process is going to check if the file has been processed
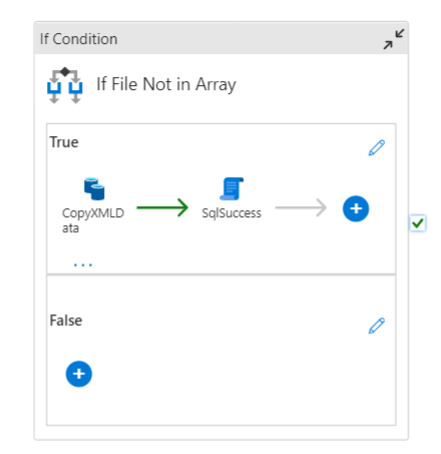
Now this is the nicest part. But it’s also a bit of a headache. When I click on the the If Condition object, this is the expression:

The expression begins with a NOT. This will evaluate to TRUE if the item().name is not contained in the variable FilesProcessed. This variable is populated (as you’ve seen above) with all the filenames logged into my table.
If this expressions resolves to true (the file hasn’t been processed yet), the copy activity will be started. If it resolves to false, nothing happens. Simply because nothing has to happen.
When a file has been processed, the name of the file gets written into the log table with some metadata like the date of the run. More columns can be added if you want to record even more metadata but be aware of the information that is available.
Copy activity
This piece is the easiest part. This just contains the source and sinks combined with the data definition. We’ll come back to this part later because there’s the little part of the file name.
After the copy activity, there’s a script. This script contains a SQL statement to write a row into the database with the filename, the datetime of the run and the status. One script for success and one for failure.
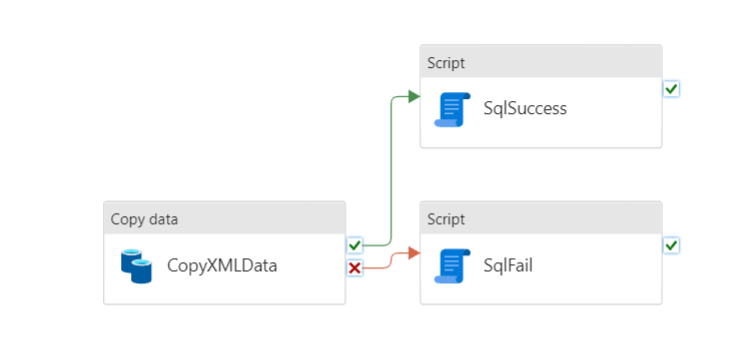
In both the SqlSuccess and SqlFail scripts, I’m inserting a row into the log database with the status. To do this in the script, I’m using this expression.

As this is a SQL Query, I can use all the goodies it has to offer. By using the @ sign with the curly brackets, I can pass in the pipeline variables. In this case the file name that is living in the item().name variable.
Full process
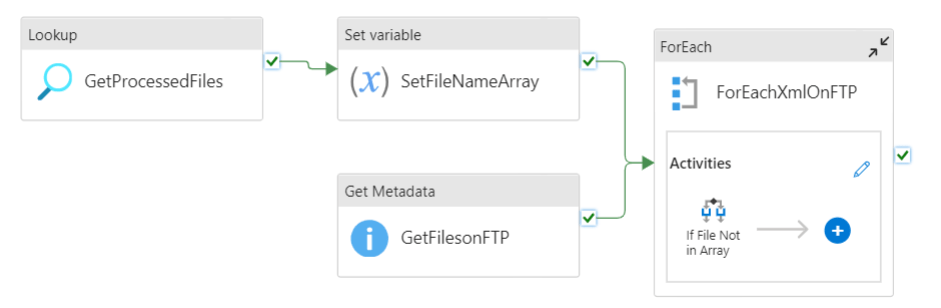
This is the entire process, from the lookup to get the processed files to the for each where the files are or aren’t processed. When you compare this pipeline, it’s not much different from the flow chart I started this blog with. Get the data, compare it and take action where needed.
In the end, this is somewhat the skeleton process of where you might want to end, but the basics can be reused for multiple usages.
Thanks for reading!
