
When Fabric released, there was a lot of noise around it. Many people have written blogs, created YouTube video’s and all kinds of other interesting things to share the love of this new tooling. Well, new? Especially when you look at Fabric data warehouse, it’s more of an iteration over Synapse Analytics Serverless Pools. As I’ve been using these to create a SQL endpoint for tooling that can’t work with Parquet files in general, this really triggered my interest.
Differences between data engineering and data warehouse
As I understand it now, Data Engineering is the Spark environment where you can build a data warehouse, Data Warehouse is the SQL environment where you can build your data warehouse. But when it says SQL, there’s no SQL Server database as such, it’s Synapse Serverless SQL Pool doing all the heavy lifting. And then again, no. Because the serverless pool doesn’t allow updates and deletes on the data, but the Fabric Data Warehouse does. The SQL Endpoint from the Fabric Lakehouse doesn’t allow datachanges, you need the Notebooks with spark to do that.
For me, it feels (at the time of writing) more like a personal preference; either building your data warehouse from Spark or from SQL. And I think both endpoints deserve a solid run to see which of the two matches best with your data and your way of working. I love SQL, no doubt there, but I have to say that the Spark notebooks are very attractive as well.
One thing to keep in mind is that the data warehouse SQL Endpoint is case sensitive.
Purpose
What is the purpose of this blog, besides checking out some of the functionality of the Microsoft Fabric Data Warehouse offering. I’m going to try and build a sort of dimensional model on my TPC-H dataset. Nothing too fancy, just the Customer, Nation and Region tables as dimensions and a join between Orders and LineItems to create a massive fact table. This table should have about 3 billion records, substantial but not really out of the ordinary. I know the Lakehouse can cope with it.
A lot of things shown here are just to test the Fabric data warehouse, not necessarily the best ways to build a data warehouse. Keep that in mind when reading the blog and the scripts.
Setup
What I didn’t do was load all the data again. In my previous blog I loaded a lot of data into the OneLake. As it is the same workspace I can use these files as a jumping point for my FabricWarehouse. This meant I had a few tables ranging from a few rows (Region) to the big table (LineItems).
The first thing I did was create a pipeline to get the data from the OneLake into my data warehouse staging schema. This is just like a regular pipeline in Azure Data Factory. One syntactical difference is that the sink is now renamed to destination.
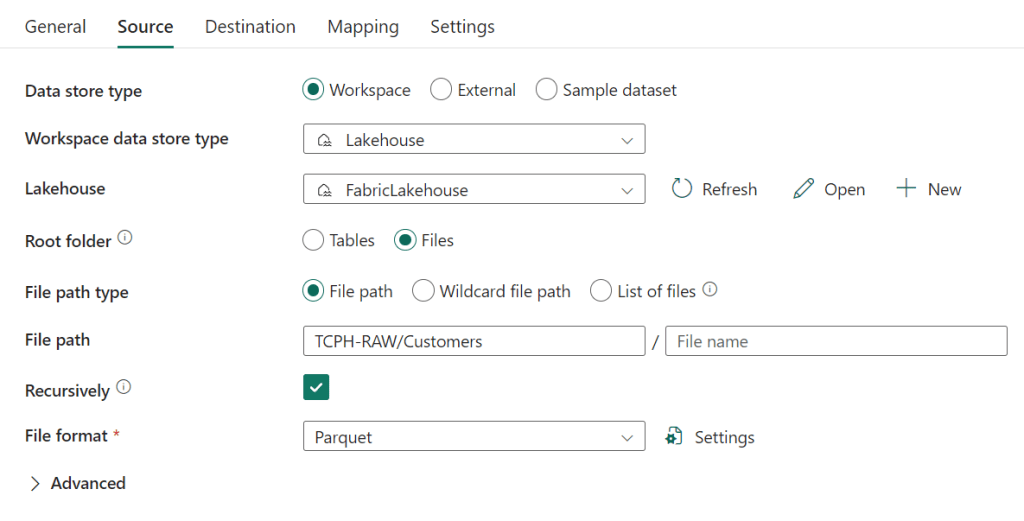
In my source definition, I set the Lakehouse as my source, pointing to the files and then set the filepath to the main folderstructure. As I’m looking for the parquet files, I can set the checkbox at the recursively line and this instructs the engine to search for all the parquet files within the folder structure. And yes, it should be TPCH-RAW but for some weird reason, I keep typing TCP-H.
The advanced part is left empty, even though you can set some nice things there as well
The destination is, again, my workspace.
At the Workspace data store type, you can choose between
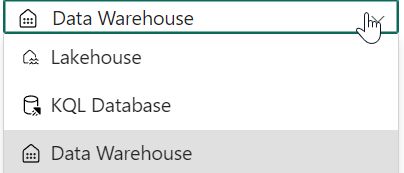
Choose your Data Warehouse and, if it exists select your table or have it created on runtime. This latter option is available via the advanced settings.

The Write batch timeout setting is one to look out for.

The default time is 30 minutes, so if you need more time to load your data (and it seems that 6 billion rows does take more time), then increase this time-out.
Then, make sure you import the schemas of your source. If you don’t, errors will appear, even if it feels like you’re just copying the files.
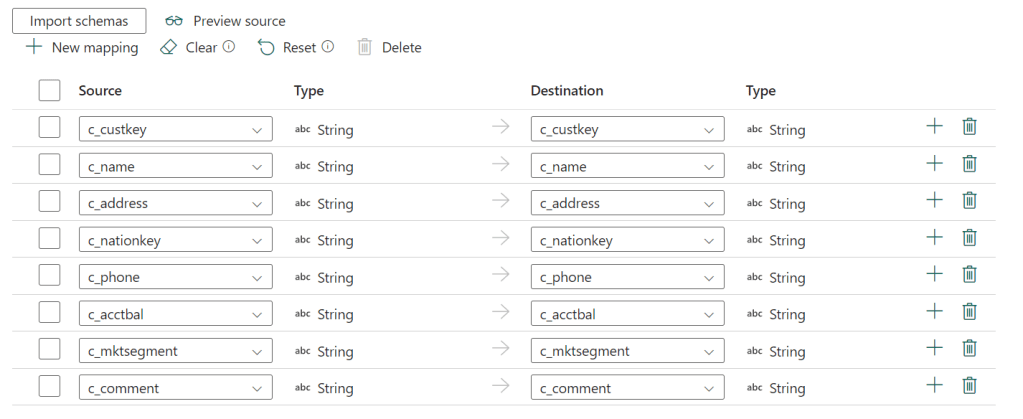
One thing I’m missing here is the option to change the data type. I can change the name in my destination, but not the data type. As my original source is CSV files without any description of the data type, I would have liked the option to change that along the way, even if my first load didn’t do that.
The last tab are the dataflow settings.

I’ve left these on the defaults. Now, there was one funny thing happening with these setting, especially the Enable staging. When I ran the pipelines, this message came up:
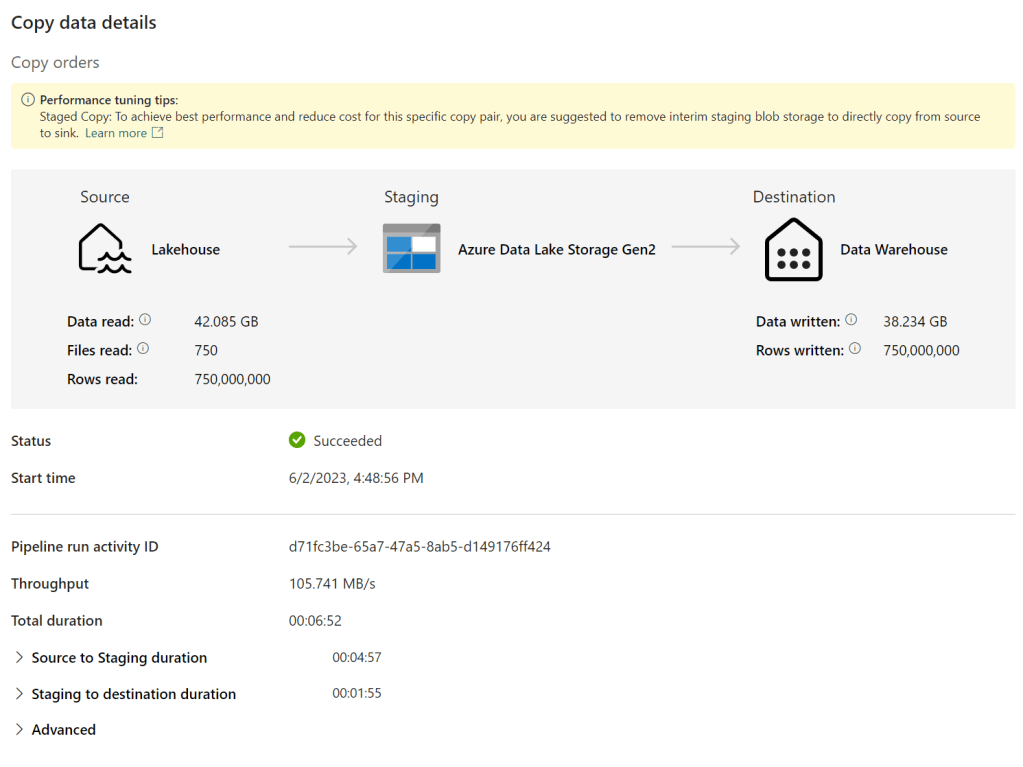
Ok, so I went to the setting and disabled the staging, expecting the transfer to go quicker.
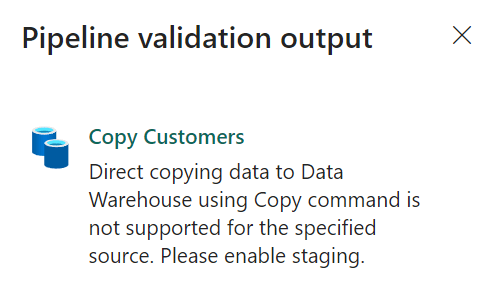
Azure says no. This error might be something to work on by the dev team of Fabric. I have submitted this as an idea.
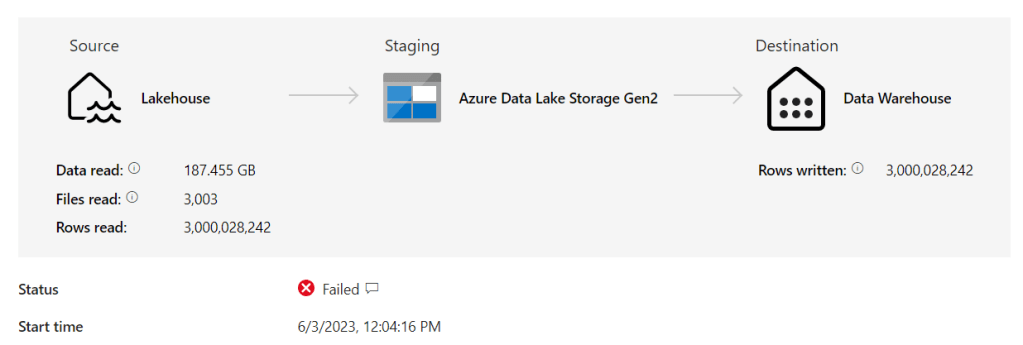
I created pipelines for all the tables, only the LineItems failed:
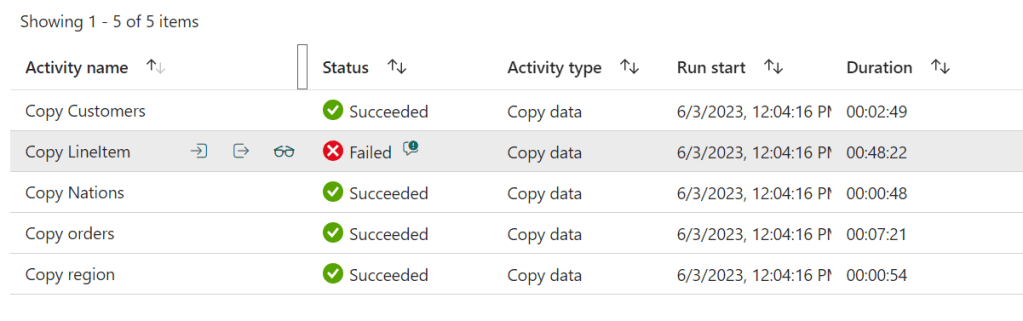
So what was the error?

The pipeline experienced a timeout. Not to be deterred, I tried it a second time and behold!

There’s one funny thing here:
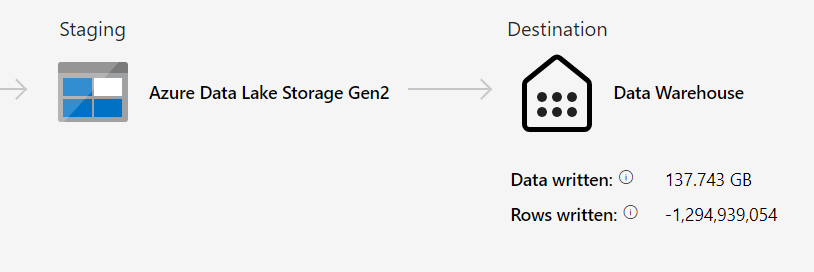
I wrote – 1.2 million rows? The first run, the one that timed-out, claims to have written a little over 3 billion rows. But as it timed out, maybe it didn’t actually write them?
Now, loading the data into a Bronze or Raw layer is just the first step; I like a model. The Copy Data Flows can do that by joining the tables in the source section and writing out the result in the destination.
Loading the data
Getting the data from the OneLake into my Datawarehouse took some time but yeah, it got there quick enough. The big one took about 17 minutes to load.
Loading the dimension tables with a script started to take a serious amount of time, combined with some weird scripting. As it’s a ‘serverless’ table you can’t use nice options like an identity column or default values in your column definition. All these things need to be taken care of in your loading script. I think that impacted my loading time.
The results:
INSERT INTO DWH.DIM_REGION (ID ,
Comment ,
name ,
regionkey ,
create_date,
change_date,
delete_date )
SELECT
ROW_NUMBER()OVER (ORDER BY r_regionkey) as ID,
r_comment,
r_name,
r_regionkey,
sysdatetime(),
'9001-01-01',
'1900-01-01'
FROM sta.region

INSERT INTO DWH.DIM_CUSTOMER (ID ,
name ,
custkey ,
address ,
nationkey ,
phone ,
acctbal ,
marketsegment ,
comment,
create_date,
change_date,
delete_date )
SELECT
ROW_NUMBER()OVER (ORDER BY c_custkey) as ID,
c_name,
c_custkey,
c_address,
c_nationkey,
c_phone,
c_acctbal,
c_mktsegment,
c_comment,
sysdatetime(),
'9001-01-01',
'1900-01-01'
FROM sta.customers

Loading Fact_Orders failed after 1 hour and 10 minutes.

The query is, of course, horrible and almost impossible to load at once. So let’s see if loops work.
DECLARE @StartDate datetime,
@EndDate datetime
SET @StartDate = '1990-01-01'
SET @EndDate = '1990-12-31'
PRINT @StartDate
WHILE @StartDate <= '2000-01-01'
BEGIN
INSERT INTO DWH.FACT_ORDERS (
ID ,
orderkey,
orderdate ,
linenumber ,
partkey ,
quantity ,
extendedprice ,
tax ,
customerkey ,
nationkey ,
regionkey,
create_date,
change_date,
delete_date
)
SELECT
ROW_NUMBER()OVER (ORDER BY O.o_orderkey, L.l_linenumber) as ID,
O.o_orderkey,
O.o_orderdate,
L.l_linenumber,
L.l_partkey,
L.l_quantity,
L.l_extendedprice,
L.l_tax,
O.o_custkey,
C.c_nationkey,
R.r_regionkey,
sysdatetime(),
'9001-01-01',
'1900-01-01'
FROM sta.orders O
inner join sta.LineItem L on O.o_orderkey = L.l_orderkey
and O.o_orderdate >= @StartDate
and O.o_orderdate <= @EndDate
inner join sta.customers C on O.o_custkey = C.c_custkey
inner join sta.nation N on C.c_nationkey = N.n_nationkey
inner join sta.region R on N.n_regionkey = R.r_regionkey
SET @StartDate = DATEADD(YEAR,1,@StartDate)
SET @EndDate = DATEADD(YEAR,1,@EndDate)
PRINT @StartDate
END
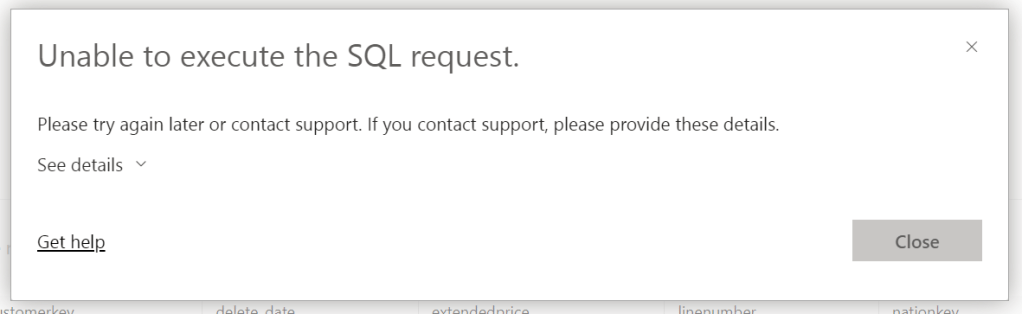
Unfortunately, the same error. So, fair to say that loading about 3 billion rows into a table doesn’t work from the SQL pane. I could write a stored procedure to fix this by looping through the data either row by agonizing row or some set based process. I think it’s fair to say that a regular SQL instance would have choked on this amount of data as well.
Indexing
If loading is slow, maybe an index will help?

You can’t create an index (yet) in the Fabric data warehouse.
Dataflow
So let’s see if a dataflow can help me out. From the homepage of my Fabric Warehouse I added a pipeline, choosing a dataflow and ended up in Power Query window. There I can choose the following options as data source:

Hmm, Datamarts. Those are new to me. But for now I want to load data and I can choose Lakehouse as a source. I can’t get to my own created staging but I can get the files I loaded in my previous blog.

Ok, let’s use dim_customer, dim_nation, dim_region_c and fact_order to load my new fact. The next thing I know is I’m looking at a PowerBI PowerQuery pane window screen. And feeling stumped. Why? Well, I’ve always been able to avoid PowerBI (or any reporting tool for that matter). My preference lies with preparing the data to make sure the people presenting it can do their job. Let me fool around with loading, performance and security on the back end of a data warehouse and let the reporting people shine where they can.
Querying the data
I wanted to get a feel for the query performance. So I tried to come up with a query that would give me some information on the data. That one hurt the system. And, it wasn’t a really fair one as the data wasn’t distributed along the column I was selecting on.
The query I used was this
select o_custkey,
YEAR(CAST(o_orderdate as date)) as OrderYear,
MONTH(CAST(o_orderdate as date)) as OrderMonth,
Count_big(1) as [number of orders]
from sta.orders
where cast(o_orderkey as bigint) <= 100
group by o_custkey,
YEAR(CAST(o_orderdate as date)) ,
MONTH(CAST(o_orderdate as date))
The query result from a performance point of view, the actual results are uninteresting.

As a comparison, I ran the same query in Spark
from pyspark.sql.functions import col, year, month
df = spark.read.format("parquet").load('Files/TCPH-RAW/Orders/*')
df = df.withColumn('Year', year(col("o_orderdate")))
df = df.withColumn('Month', month(col("o_orderdate")))
df_filtered = df.filter(df.o_orderkey <= 100)
df_subset = df_filtered.select(df.o_custkey, df.Year, df.Month)
df_count = df_subset.groupby([df_subset.o_custkey, df_subset.Year,df_subset.Month]).count()
df_count.sort(col("count").desc()).show(truncate=False)
This code ran as follows
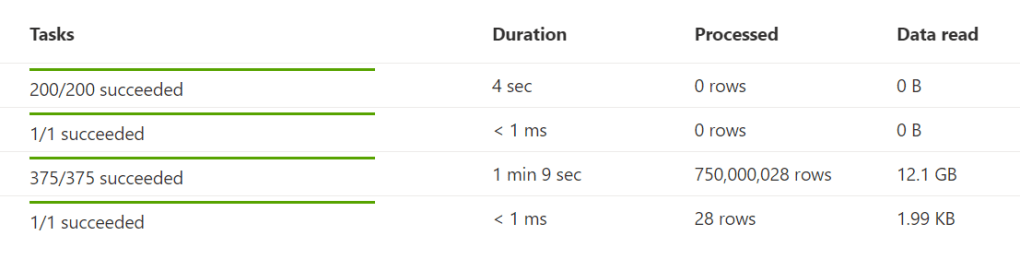
In this case, I could argue that Spark is much faster in returning data then the SQL engine. Turning the tables should be just as easy AND remember, it’s still in preview. Who knows what’s happening with power distribution under the covers.
Stored procedure to load data
As I wrote at the start of this blog, you can use stored procedures as well against the data warehouse. So let’s see what happens if I run a procedure that loads a year, depending on a variable.
CREATE OR ALTER PROCEDURE sp_loadFabricFactYear
@year INT
AS
PRINT 'You have chosen to load the year: ' + CAST(@year AS VARCHAR(4))
DECLARE @StartID INT,
@loadingYear DATE = CONVERT(date,concat(@year, '-01-01')),
@loadingYearEnd DATE = DATEADD(YEAR,1,CONVERT(DATE,concat(@year, '-01-01')))
PRINT 'Calculated startdate: ' + CAST(@loadingYear as VARCHAR(10))
PRINT 'Calculated enddate: ' + CAST(@loadingYearEnd as VARCHAR(10))
BEGIN
INSERT INTO DWH.FACT_ORDERS (ID,
orderkey,
orderdate,
linenumber,
partkey,
quantity,
extendedprice,
tax,
customerkey,
nationkey,
regionkey,
create_date,
change_date,
delete_date)
SELECT ROW_NUMBER() OVER (ORDER BY O.o_orderkey) as ID, /* I really really miss the Identity column! */
O.o_orderkey,
O.o_orderdate,
LI.l_linenumber,
LI.l_partkey,
LI.l_quantity,
LI.l_extendedprice,
LI.l_tax,
O.o_custkey as customerkey,
N.n_nationkey,
N.n_regionkey,
sysdatetime() as create_date,
'1900-01-01' as change_date,
'9001-01-01' as delete_date
FROM sta.orders O
INNER JOIN sta.LineItem LI on O.o_orderkey = LI.l_orderkey
INNER JOIN sta.customers C on O.o_custkey = C.c_custkey
INNER JOIN sta.nation N on C.c_nationkey = N.n_nationkey
WHERE O.o_orderdate >= @loadingYear
and O.o_orderdate < @loadingYearEnd
END
This is a bit of silly code, mainly to show you that you can update tables and insert data with a stored procedure. And, as we’ve seen before there a big chance this fails a there’s a lot of data in a single year.
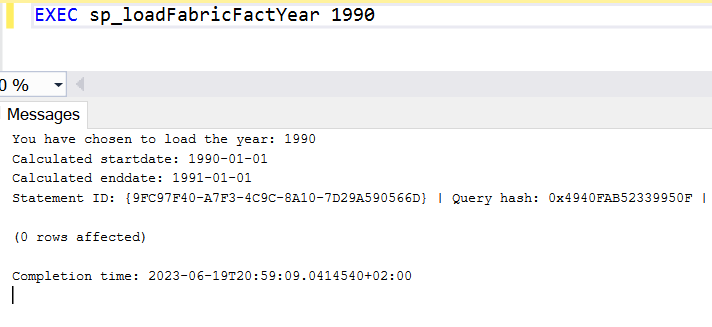
1990 hasn’t got any records, 1996 has. Let’s see what happens there. As this process was trundling along, I wanted to see how many rows were inserted. Or at least if rows were inserted.
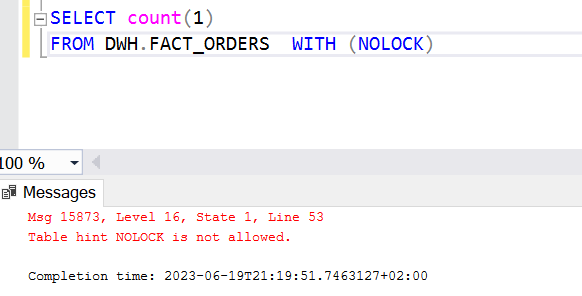
Without the hint, the result was 0 rows. I’ve seen that behaviour before when files were being written in the lake, you can’t access them and have to wait until the process finishes.
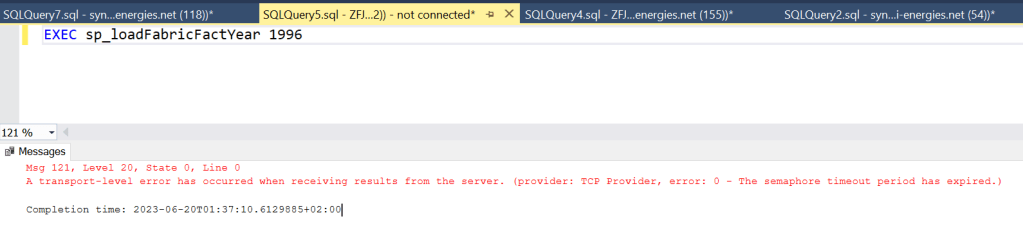
After three hours and 15 minutes (or thereabout), the query died. You can read more about this error here. As I really want some data to load into my new table, I changed to code to load just one day. I added variables for month and day and changed the end-date variable from 1 year later to one day later.
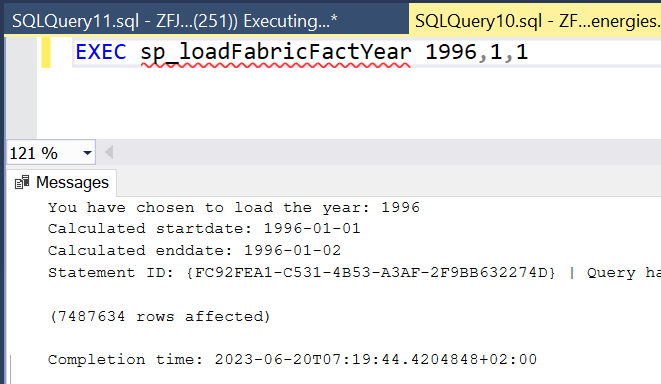
Let’s see if the data looks any good.

Loading 7.487.634 rows in a little under three minutes. That averages at about 43.533 rows per second.

Digging a little deeper
I was wondering where the pain was. Was it in the reading of the data or the writing. So I took the query from my stored procedure and executed it, without showing the results on my screen (to eliminate the time it takes to transfer the 7.4 million rows from Azure to my SSMS. And, also wondering if the ROW_NUM function was having too much fun, I executed the query with and without that function. Unfortunately, SET STATISTICS TIME, IO ON isn’t supported in this environment, so getting the runtimes is a bit harder.
Let’s just say this wasn’t a wise choice. If the process as a stored procedure can finish in less than three minutes, just selecting the data without presenting the results should run quicker. As it doesn’t, my guess is that SSMS is still getting the resultstream but it’s just not showing it.
Back to the Fabric Query Window
The query pane window in Fabric is much better in this respect. On the one hand, I can’t tell it to show no results. On the other hand, it’s smart enough to know that no human is going to read all those rows, and it stops at 10.000 records!
Now, to the results I wanted to see.

My query with the ROW_NUMBER operator started at 05:59:09 and ended at 06:02:15, taking 2 minutes and 16 seconds. Without it, the query started at 06:02:15 and ended at 06:03:57, taking 1 minute and 42 seconds. Maybe some caching helped, maybe not having to sort the records helped. In any case, the latter was about 30 seconds quicker.
Checking Azure Data Studio
Finally, I wondered what ADS could do with my check query.

Just like SSMS, it tried to get all the rows into the result pane. Bad idea and to prevent the app from crashing or overloading my laptop, I killed the process. In this case, using the Fabric interface is your best bet.
Concluding
Thank you for sticking with me along this long blog. A few takeaways from this blog.
- Fabric is still in preview, it is missing some options crucial to creating a SQL based data warehouse, like an identity insert and performance metrics like time and io statistics
- Using SSMS or ADS to develop query’s is fine, running them against Fabric is a less brilliant idea if you expect many rows in return
- In the current state, running a full load into a large fact can’t be done in a single run, you need to split it up logically (Time, ID or whatever your fact supports)
- The auto save function of query’s in Fabric will save you sooner or later
- Rethink your data architecture; do you still need all the layers (bronze, silver, gold for example) in your data warehouse or can you leverage the delta lake for raw and history and only build your model in the data warehouse?
- Think about the way you should distribute your data to make sure you maintain your performance.
All things considered, the Fabric warehouse has a lot of potential and I’m really excited to see more development going into it to make it GA ready.
Thank you so much for reading!

Thanks for your blog. To be honest, I’m quite disappointed with Fabric, as I’ve found it to be quite messy and full of bugs
LikeLike
Hi Ali,
Don’t forget that you can report bugs and ideas to Microsoft. I’ve never come across software that has no bugs. If you’re running into something that breaks your work, let them know, it’s the only way Microsoft can improve.
LikeLike