
In my previous four blogposts, I’ve shared some first impressions and small things I discovered since the preview release. Again, the preview release. New features are added, bugs are fixed and additions are released. When I asked if there’s a GA release date, there was no answer. And I can guess why, it’s hard to estimate when the product is good enough to release and support. One thing Microsoft doesn’t want is to release a product that is impossible to adopt and will therefore fail. When you read this blog when Fabric has gone GA, you might get a good laugh at these observations ;).
Opinions
So, these preliminary opinions I’m offering now are based on the preview I’ve worked with and will keep on working with.
That’s the first observation, I’ll keep on working with this. Why? To be honest I think it’s a step forward from the Data Factory, Synapse, PowerBI experience. Everything together in one product makes life easier. Even though I’m having a really hard time adopting to the interface. I keep selecting the wrong buttons to get stuff done. Then again, only being able to do this after working hours and during the weekend may have something to do with that. But making the interface a little more intuitive would really help me.
For me, Fabric isn’t a completely new tool, it’s an iteration in the lifecycle of Synapse, ADF and PowerBI. It’s an excellent iteration at that too. But, there’s Purview, Machine Learning and IoT as well? Yes, there is, but those aren’t my focus areas. There are colleagues who are way more proficient in these areas. I’m not going to pretend I am.
When Fabric was released, my expectation was that Data Factory would be fully integrated in Synapse analytics. As it’s still a ‘resource’ within Fabric, I was wrong.
Missing features
I’m missing SQL features in de data warehouse part. Simple things like an identity insert or a way to sort my data to enhance data retrieval in the SQL pane would make performance life easier. Then again, as it’s all based on the OneLake with the delta files, maybe the way forward in data warehousing are the Spark notebooks. You can create column based statistics in the SQL endpoint to enhance query’s. The funny thing is, this link describes that auto created statistics are yet unavailable, yet when I check my wonky warehouse:

Maybe the docs are running a little behind. Or my queries were heavy enough to trigger some sort of process.
As I mentioned, I’d like some updates in the interface; tabs for instance to easily switch between screens without stopping running workloads. I’ve had it happen a few times that a query ran, I switched temporarily to the main overview and then find out that the query just quit. Yes, I see the reasoning but show a message like Fabric does with the PowerBI pane. Then again, I can run my query’s from SSMS or ADS which is fine as long as the result set isn’t too big.
Another thing I’m missing (or maybe doing wrong) is the ability to change data types. I like to have some control over my data types, having everything in a nvarchar(max) effectively isn’t really helping my query’s to filter on date, time etc.
It is possible with the OneLake tool you can use inside your Windows Explorer to browse in your OneLake. Nevertheless, if you enable the Fabric trial from the PowerBI experience, you cannot find your OneLake in your Azure tenant. As a control freak, I’d like to know where my data is, if only from a governance point of view.
Microsoft loves to see your ideas come in, so take a look ideas.fabric.microsoft.com. If you never mention the features you miss, no-one will know them or be able to vote them up.
Performance
When working in the data engineering interface, I was truly amazed at the performance of the Spark engine. Until then, I had played a bit with Synapse, but as the bigger clusters aren’t exactly cheap I’d never tried anything more than small clusters and small amounts of data (Adventure Works and Wide World Importers size data). The Fabric preview runs on a F64 cluster and that one has some serious oomph under the bonnet. Processing my ridiculous 6 billion rows dataset in minutes, I’d say SQL Server is jealous. But as it’s hard to find out how much power is unleashed in the background, it’s hard to decide what Fabric Capacity Unit would suffice for regular workloads. For most of our customers, it would be an adventure to work it out.
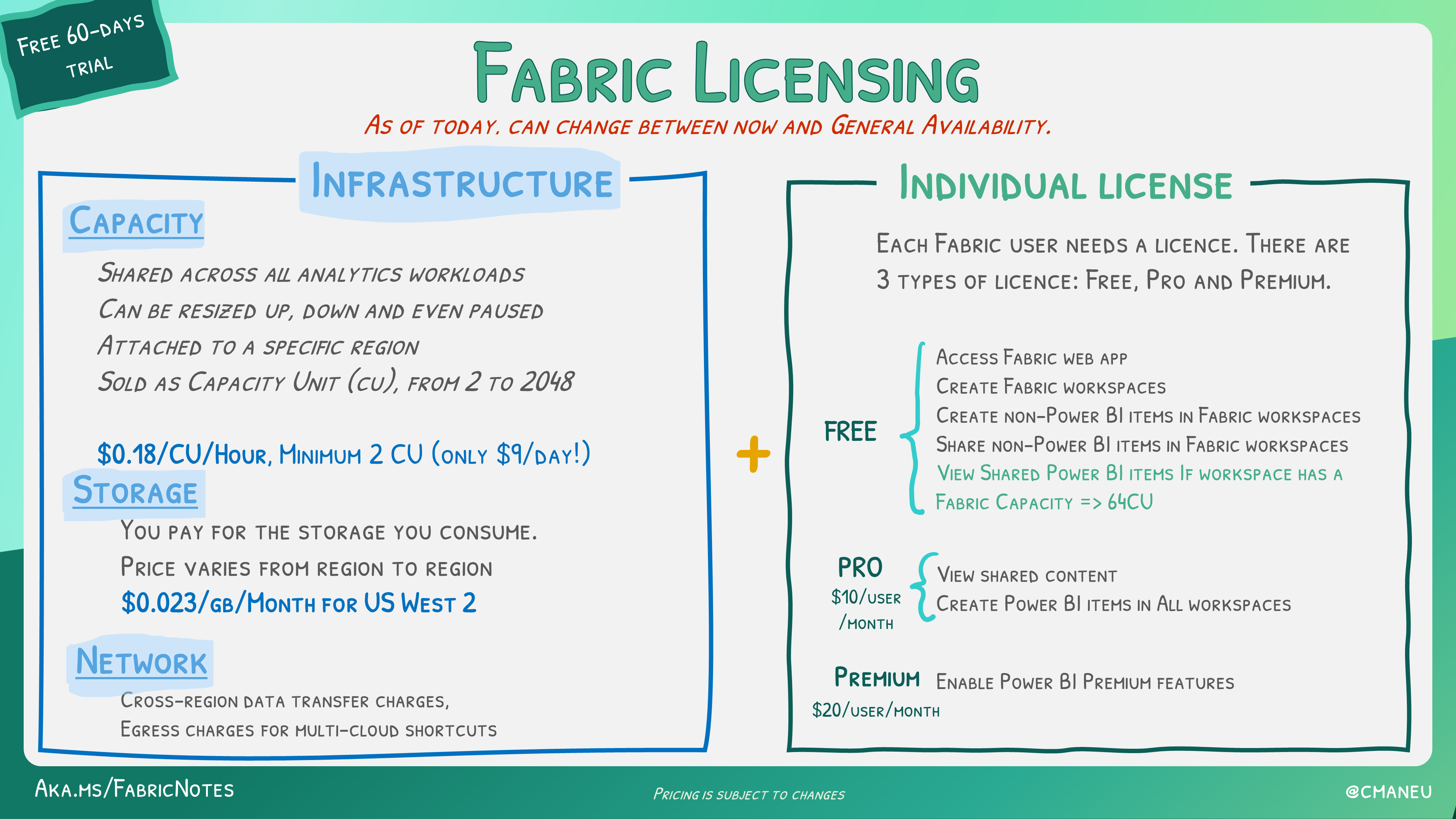
Licensing
The licensing model seems fairly straightforward. Almost to simple even.
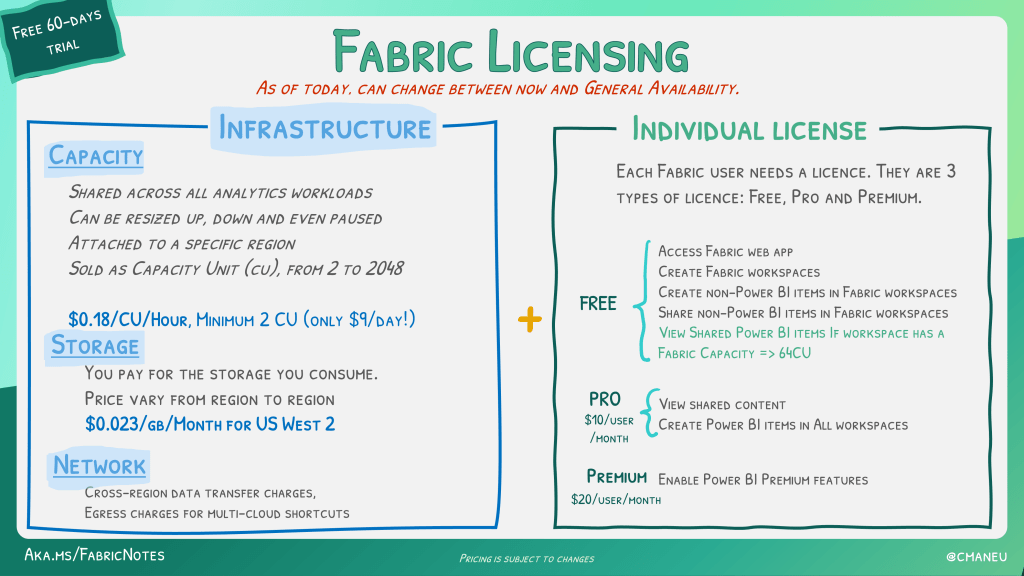
Then again, maybe I’m overthinking this. You can find prices for your own region to get a feel for what it might cost you on a monthly basis. There are some variables of course. One thing that isn’t clear to me yet is will the PowerBI reports keep working, even when Fabric is in a sleeping state. Another big question is the performance of the lower end capacity units. For now, they seem quite strong but all this is subject to change (preview, remember?).
Research from a smart intern
Whilst I was writing this blog and trying to figure out everything written here, we had an intern, Jorn Wiersema, doing research on data platform architectures, their quality and how to manage them. His research focuses on the different architectures we’re offering to our customers. During the company presentation (which he nailed by the way), he touched on the different offerings from Azure. Afterwards, Jorn was kind enough to send me a copy of his paper to dig into.
It’s a thorough research into our company, but he created a nice comparison between different options within the current Azure offerings; Data Factory, Synapse Analytics and Databricks.
Jorn describes a number of these architectures and already included Fabric as it can house all the different architectures (classical data warehouse, data lakehouse etc) within one solution. As he describes it, it’s a long term opportunity.
And I have to agree with him, Fabric now is in Preview with an unknown GA data. After going GA, there are most probably a number of wrinkles to iron out. As there are with any piece of software. But the plethora of possibilities is not to be missed.
Before moving on, I’ve heavily summarized findings from Jorn’s work. Any error in the above three paragraphs are mine, not his.
My daily job?
Now, will Fabric change my work? Absolutely. There will be customers who’ll want to migrate from their current setup to Fabric. And who’ll want to leverage the Spark engine. This means as a consultant, I have to brush up my Spark knowledge. As there’s a direct connection with PowerBI, at least basic knowledge of PowerQuery is in order as well. Something I’ve been able to evade until now. Will the infrastructure part fade away? I don’t think so, yet. There are customers who like to use other tools or technologies to build and visualise their data warehouse. For them, another mix of tools might lead to their best solution.
In the last few years, I’ve gotten used to deploying a lot of Azure infrastructure to support data workloads and landing zones. This won’t go away as there will always be customers who want full control over every moving part. Customers who haven’t got the knowledge and/or capacity to manage all the resources might be much better off with Fabric. One thing to keep in mind is to make sure unused capacities are turned off / sent to sleep.
The fact that it has built-in governance and lineage through Purview is a wonderful addition, though it still lacks the ability to work out what happens in my stored procedures. Then again, who doesn’t scratch their head with those.
As an Azure and data enthusiast, adding a new toolset to my toolbox is really cool, though it poses challenges as well to keep the knowledge up to date. Coming from a SQL background, my instinct is to go for the SQL endpoints, but I might just have to rethink that when working with large datasets with high performance requirements.
Thanks for reading and please leave your thoughts in the comments!

{kind=link}
One thought on “Microsoft Fabric, impact on my daily work”