
Or, how SQL Server behaved differently than I expected but managed to process quite a lot of rows before giving up.
Let’s begin
We have a customer that would like to see the actual value of their stock in a table. They buy their stock at different times and at different prices. Calculating the stock is not just multiplying the number of items times a fixed value. If only it were this simple. So what I need to write is a query that collects the current stock amount and then digs into the tables where the prices are buried for that stock.
Now, the stock can be 20 items, bought in 8 sessions for 6 different prices. I can’t use the latest price to calculate the value but I have to dig through the table with the prices to sum the value. For every record in the table with prices, there’s the amount of items. I need to sum that amount and check it against the current stock to see if everything is covered or that a next row is needed.
I know it sounds difficult, so here’s a (simplified) example.
Example
| ID | ItemNumber | NumberOfItems | StockDate | ShopID |
| 1 | 1234 | 25 | 14-12-2023 | 5 |
| ID | ItemNumber | ItemsPurchased | Price | PurchaseDate | ShopID |
| 1 | 1234 | 10 | 4 | 01-12-2023 | 5 |
| 2 | 1445 | 25 | 8 | 01-12-2023 | 5 |
| 3 | 1234 | 10 | 7 | 28-11-2023 | 5 |
| 4 | 1234 | 8 | 12 | 16-11-2023 | 4 |
| 5 | 1234 | 9 | 12 | 16-11-2023 | 5 |
In the example above, a simplified version of the problem is shown. Luckily, the company is using FiFO. First In, First Out means that the oldest products are sold first. In my query this means I can order the rows by date descending. Most of the stock can be of the most recent purchase. In the above example, this leads to 10 * 4 + 10 *7 + 5 * 12 = 170. Just working your way from top to bottom adding up the price until the stock matches the sum of items purchased.
Write the query
To build this query, I thought to be very savvy and use one big set of CTE’s to fly through the data. Because my experience with CTE’s is excellent. Relatively easy to read, it has some nice tricks up it’s sleeve (recursion) and it usually performs good enough. To show you an query example, this is what it started with:
/*
Clean testtables
*/
DROP TABLE IF EXISTS #purchaseTable
DROP TABLE IF EXISTS #stock
/*
Create testtables
*/
CREATE TABLE #purchaseTable (
id INT identity(1, 1)
,itemsPurchased INT
,Price INT
,productid INT
,purchaseDate DATETIME
,Source VARCHAR(20)
)
CREATE TABLE #stock (
id INT identity(1, 1)
,stock INT
,productid INT
)
/*
Add data
*/
INSERT INTO #purchaseTable (
itemsPurchased
,Price
,productid
,purchaseDate
,Source
)
VALUES (20,10,1,'2023-12-01','pakbon')
,(15,12,2,'2023-12-02','VVP')
,(8,7,3,'2023-12-03','Order')
,(12,8,1,'2023-12-04','VVP' )
,(20,10,3,'2023-12-01','VVP')
,(15,12,1,'2023-12-02','pakbon')
,(8,7,5,'2023-12-03','Order')
,(12,8,7,'2023-12-04','Order')
,(20,10,4,'2023-12-01','Order')
,(15,12,8,'2023-12-02','pakbon')
,(8,7,6,'2023-12-03','VVP')
,(12,8,9,'2023-12-04','pakbon')
,(12,8,1,'2023-11-04','pakbon')
,(12,8,1,'2023-11-03','Order')
INSERT INTO #stock (
stock
,productid
)
VALUES (25,1)
,(10,2)
,(18,3)
,(16,4)
,(25,6)
,(10,5);
/*
Set of common table expressions to process the data and create a result set.
*/
WITH prep
AS (
SELECT a.productid
,a.stock
,b.itemsPurchased
,b.purchaseDate
,b.Price
,a.stock - b.itemsPurchased AS [stock minus purchase]
,SUM(b.itemsPurchased) OVER (
PARTITION BY a.productid ORDER BY purchaseDate DESC
) AS runningStockSum
,ROW_NUMBER() OVER (
PARTITION BY a.productid ORDER BY purchaseDate DESC
) AS rn
,Source
FROM #stock a
INNER JOIN #purchaseTable b ON a.productid = b.productid
)
,prep2
AS (
SELECT productid
,stock
,itemsPurchased
,runningStockSum
,purchaseDate
,[stock minus purchase]
,Price
,rn
,max(rn) OVER (PARTITION BY productid) AS maxrn
,isnull(stock - lag(itemsPurchased) OVER (
PARTITION BY productid ORDER BY purchaseDate DESC
), stock) AS calculatedStock
,Source
FROM prep
)
,prep3
AS (
SELECT *
,CASE
WHEN (
LAG(runningStockSum) OVER (
PARTITION BY productid ORDER BY purchaseDate DESC
) - stock
) > 0
THEN 0
ELSE 1
END AS userowmarker
FROM prep2
)
,agg
AS (
SELECT *
,CASE
WHEN rn = 1
AND maxrn > 1
THEN Price * itemsPurchased
WHEN rn > 1
THEN Price * calculatedStock
WHEN rn = 1
AND maxrn = 1
THEN stock * Price
END AS stockprice
FROM prep3
WHERE userowmarker = 1
)
SELECT productid
,stock
,sum(stockprice) AS stockValue
,Name = STUFF((
SELECT DISTINCT ',' + Source
FROM agg b
WHERE a.productid = b.productid
FOR XML PATH('')
), 1, 1, '')
FROM agg a
GROUP BY productid
,stock
ORDER BY productid ASC
With a small testing set there were some signs that the query wasn’t flying. On the contrary, it was leisurely strolling about. Smelling flowers, admiring butterflies and then turning back to me handing a whole set of 7 rows. The values were correct, the timing less so. When you need 5 minutes to calculate 7 rows, you can imagine what happens when there are 6.5 million rows to be calculated.
If you’d like to get some insight into the plan, follow this link.
One of the things that drew attention is this thingy here:

The reason why this Table Spool is generating this amount of rows is this:
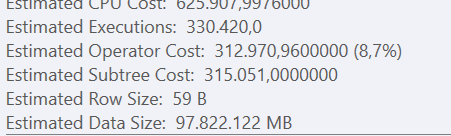
The source table has about 6.4 million rows but with enough executions (in this case it started to reread the dataset 330.420 times) you’ll end up with over 1.5 trillion rows. Let’s just say this is not good. The poor engine died on this. If you must know, the database is an Azure SQL Database General Purpose Gen5 with 24 cores.

After 8 hours I got a connection semaphore time-out. And it had only processed 890.258.162.332 of the 1.738.660.127.400 rows. In a way, processing this amount of records is a feat in itself. And a testimony to my failing query skills.
Fixes
There was some pain in source tables, fixed by creating specific statistics. This meant the estimates were spot on, the plan changed slightly but not enough to get me through.
There seemed to be some trouble with the first CTE, so I changed it to a query writing to a temp table. That did help, it shaved over a minute off my initial querytime but not enough. To ease the load on the instance, I switched from doing it all at once to looping through two levels within the data, let’s call them shops and products. I built a while loop for each shop and then nested a loop for each product. It seemed to work and I got the runtime down, the 7 rows now took about 10 seconds. In the larger dataset, each combination took about 750 ms. That’s OK, but then again, 6.5 million rows to process. It would take about 1350 hours to process all the data, not good enough for a process that needs to run on a daily basis.
As the target table has indexes, I thought to make a smart move and disable them. Only to find out my query took way more time, about 40 seconds for the 7 rows. Not good, let’s get them back. To add some context to this finding, I’m just updating two columns in an existing table, not adding rows, so the indexes probably helped me in finding the correct record to update and removing the indexes (only the non-clustered ones) was a less smart move.
What if…
Now, earlier on I had rebuilt a CTE to a query writing to temp table. What if the CTE’s were not the best option? Just to eliminate the option, I rewrote the query where each CTE step got written to a temp table. I removed the product loop and checked the 7 rows data set. Within a second it was done. I had to check multiple times to make sure I hadn’t messed something up. But no, it was quick. So I took the entire data set (the one that broke the night before after 8 hours of work). And it flew through in less than 5 minutes. No more sniffing of daisies, just a full on bunch sprint to the finish line.
I would love to show you the different query plans used within the new process, but for some reason SSMS is only able to export the first query plan. My SentryOne/Solarwinds Plan explorer can’t connect to the client database because Azure AD reasons. Let me know if you have a trick, other than selecting and running an isolated part of the query.
Are CTE’s good or bad?
Now, I was, and still am, a huge fan of CTE’s. But there are limitations to them, and it seems I ran into one of them :). My main learning from this process is to always look beyond what you think might be the best option, to borrow from Brent Ozar, try and think like the engine. Try to understand what the execution plan is telling you, using Hugo Kornelis as a reference.
A part of me is still wondering if a recursive CTE might have gotten the job done even easier, but with the complexity of the data, I just couldn’t get my head around it to build a recursive one. Is this the best solution? Maybe not but it’s good enough and there are other, more urgent issues to dig into.
Thanks for reading!

CTEs are great for recursion, readability and also for writing DML queries now and then. But my experience with performance is not positive. SQL will simply plug the text of the CTE where you use it in the query and the more CTEs that are used, the more complex queries get for the optimizer. Your approach of materializing is one of my best practices. I’m a Pareto-principle adept (20% effort, 80% effect). When I come across a slow query with many CTEs, the first thing I try is to materialize some or all CTEs to see what the effect is. Regularly, as you saw, the query will become snappy and I’m often already content. It’s sometimes the upbeat to investigate more closely to understand what is going on. For large complex queries I have good experience with breaking down the query in smaller subqueries and materialize in between, like you have done here. Tuning a large complex query in other ways is in my experience often the path of most resistance. The break-down approach is a good way to filter data as soon as possible.
LikeLiked by 2 people