
Getting data from a database with Change Data Capture enabled
In my last blog, I pulled all the data from my table to my datalake storage. But, when data changes, I don’t want to perform a full load every time. Because it’s a lot of data, it takes time and somewhere down the line I’ll have to separate the changed rows from the identical ones. Instead of doing full loads every night or day or hour, I want to use a delta load. My pipeline should transfer only the new and changed rows. Very recently, Azure SQL DB finally added the option to enable Change Data Capture. This means after a full load, I can get the changed records only. And with changed records, it means the new ones, the updated ones and the deleted ones.
Let’s find out how that works.
Enable CDC
Enabling CDC on the database is nothing more than this
EXEC sys.sp_cdc_enable_db
When the query completes, CDC is enabled. You can check the result like this
select name,
is_cdc_enabled
from sys.databases

But, next step is to enable CDC on the tables. Because that’s the change I want to capture. To enable CDC on my posts table, this is the most basic version on how to do this
sys.sp_cdc_enable_table @source_schema = 'dbo',
@source_name = 'Posts',
@role_name = 'dbo'
This query enables the CDC on my dbo.posts table and members of the dbo role can access the data. In your production environment, you’ll want to handle this differently with roles and even filegroups. Click here for a more elaborate description on the parameters you can use.
Use CDC in ADF
Now the next question is, how can I use CDC in my ADF pipeline. Because it’s all fun and games that the database is keeping track of the changes, but I need those changes.
In my previous blog, I showed how to dynamically load multiple tables. This time, I’m going back to just one table. Reason being that I want to make sure I can track all the data changes. I’ve used the Posts table from my database and right now, there are no changes. Which is my starting point. I’ve shown you before how to create linked services and data sets, I won’t bore you with those again. The linked services are to my Azure SQL DB and my Azure Data lake. The linked service to my data lake is prepared for just one file. A CSV file this time because I want to be able to show the contents, and in a CSV that’s easier than in a parquet file.
Source dataset
My dataset to the source table is a bit different. It’s no longer aimed at my dbo.posts table, but at the table that contains the changed data capture results.
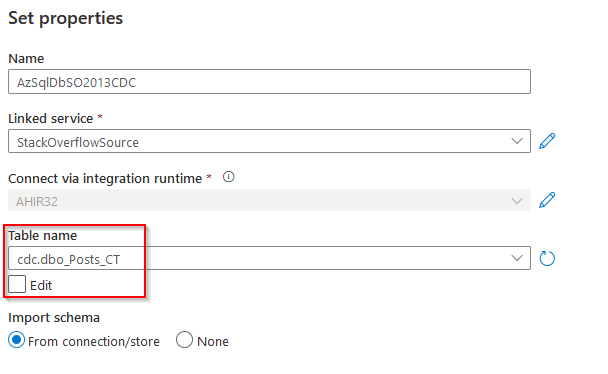
This dataset will point me to the changed data set instead of the full table.
Next up, create a pipeline to host all the activities. Then create a lookup. Last time round, the lookup was used to get the tables for the dynamic loading. This time, I’m using it to count the number of changed records. Because I don’t want to start a copy job when there’s nothing to copy.
Get number of changed records
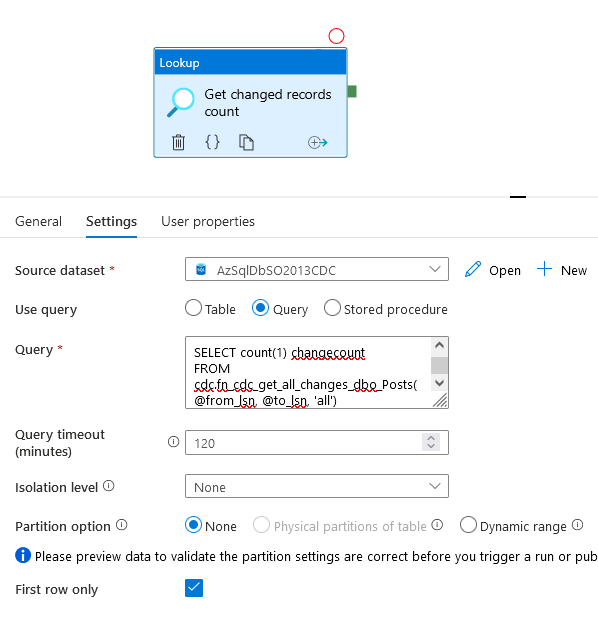
Now, how do we get the number of changed records, especially from the previous run. There’s a query for that
DECLARE @from_lsn binary(10), @to_lsn binary(10);
SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_posts');
SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE());
SELECT count(1) changecount
FROM cdc.fn_cdc_get_all_changes_dbo_Posts(@from_lsn, @to_lsn, 'all')
Off course, this query changes for every table that gets invited to the CDC party. There are two variables I need to discuss a bit. The @from_lsn and @to_lsn variables.
The @from_lsn variable will help me to get the data from the point that the CDC has been enabled. The system function that populates the variable does this for me by getting the correct lsn.
The @to_lsn variable applies a limit on the lsn. It gets the last LSN that’s valid for the moment the query is run. This means that if there are changes after you run this query, they won’t get counted. For now, in the demo this doesn’t really matter. But when you’re running in a production environment, you don’t want to miss out on data. You’ll need to get a proper definition of your start and end times. More on that later, but it is important to understand what these variables do.
IF conditional
Now that I’ve can get the result back, I need to decide what to with it. I’m going to add an IF object.

I have to tell the If what to if, if you get my point.

I have to create an expression that the IF conditional can work with. It has to result into a boolean. So the expression, or formula, has to result in something that’s either true or false. In my case, I want to test if the number of changed rows from the lookup is larger than zero. If it is, then the expression should be true, else it’s false. Now I’m really hoping there’s no bug where the number from the lookup can be negative.
When I’m going to the dynamic content editor and click on the output from my lookup, this is what I get
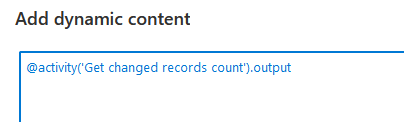

First, I have to add the .firstrow.changecount to get the result of the query. Firstrow because the lookup is only returning the firstrow, that’s where the data is residing. Changecount because that’s the name of the colunm in the query result.
Now, getting the number of records isn’t a boolean, it’s an integer. So I need to pad this function with something that will turn my integer result into a boolean.
Within the logical functions of the dynamic content editor, you can find this

It returns true and false (also know as booleans) and it checks integers. Cool, that’s what I want!

Returning false
Before I can test this, I have to add activities to the true and false parts of the IF object. Or one of them at least. I know that my current result equals zero, so I’m going to start with adding something in the false part. because 0 isn’t greater than 0.
What I’ve done is add the Get Metadata object in my false operator of the If conditional and connected it to my CDC dataset. I have genuinely no idea what the result is going to be, but let’s find out!

Ah, I need to set someting in my field list in the Metadata activity.
Debug
Now the pipeline validates and I can run it.

My pipeline got into the false part. This is excellent because that’s where it should be.
Returning true
When the number of records is larger than zero, the if conditional will return true and work has to be done. In my case, I want to transfer the changed records to CSV files. To do this I start out with a Copy data activity. In this activity I have to define my source and sink again. In the source, I’ve got to point to the table where the changed data resides.
DECLARE @from_lsn binary(10), @to_lsn binary(10);
SET @from_lsn =sys.fn_cdc_get_min_lsn('dbo_posts');
SET @to_lsn = sys.fn_cdc_map_time_to_lsn('largest less than or equal', GETDATE());
SELECT *
FROM cdc.fn_cdc_get_all_changes_dbo_Posts(@from_lsn, @to_lsn, 'all')
Yes, I’m using select *. This is to make life a little bit easy. You could select the columns you want. For instance changes in some columns don’t matter so you don’t take them with you. Or various other reasons and logic that are useful in your scenario. For now, I’ll stick to select *.
Apart from the columns in my table, I get a few bonus columns as well with metadata. The operation column will tell me if it’s an insert, update or delete. You could split these three streams if you’d want to into three different copy activities. For now, I’ll keep them in one.
My sink is just the dataset for the CSV file

Right, time to check out what happens when we start messing around with the data
First test, add data
First up, adding some data

Now, let’s see if the counter changes

Ok, let’s run the pipeline!

Ooh that’s nice! I’ve got the ten new records in my datalake. Agreed, wrong file format name but again, still learning by failing. Now, let’s update some rows and make sure the next file is in csv format.

Update data
I ran this script a few times:
update dbo.Posts
set ViewCount += 100
where Id <= 100
It hits 64 rows in my database, let’s see what my counter tells me. I ran the query three times and every update hits 64 rows. 3 * 64 = 192 so the data preview should show something like that. Why not 64? Well, every update I ran was a separate transaction and every transaction gets logged by the CDC.

Right, 192 updates and the 10 new rows makes it 202. Let’s see if they’re in order by running the pipeline again and checking the contents of the csv file.
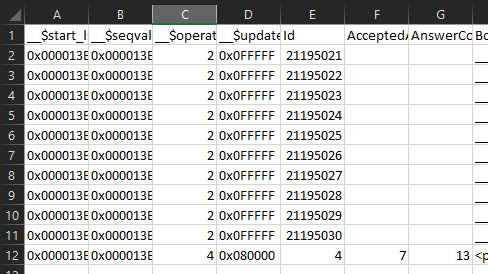
I’m getting a lot of rows back, and besides __$operation changing from 2 (insert) to 4 (update) I can see that inside the cdc table, the data is ordered by update. For your peace of mind, it’s ordered in the CSV file as well.

Delete data
Now, last test, because besides inserting and updating data, sometimes data gets deleted. I know, you shouldn’t but it still happens. CDC should track that as well. So, deleted three rows and let’s see what the CSV looks like:


Ok, so now I know the code for inserts (2) updates (4) and deletes (1). In theory, you could split those into three files and handle them accordingly.
Delta loading
But there one thing nagging. Because I’m reading the entire CDC table. Which is way less than the original table, but the amount of data will grow and before I know it I’m reading too much data for what I want to achieve. To put it differently, Now I have to make sure I’m only getting the changes after the last run.
To do this, I have to think of a window that has sort of fixed values. For example, when the pipeline starts it looks back 24 hours and it stops at the last whole hour. If it runs at 19:32 today, it get’s the data from 19:00 yesterday up to 19:00 today. Your businesslogic will differ but let’s work with this one for now.
How can I accomplish this. Azure calls this a tumbling window. Even though the link refers you to advanced analytics stuff, the theory remains the same. A fixed window without overlapping data. This means that you should get all the changed data without missing records.
But how to get that to work.
Pipeline Variables
First up, I have to create two Variables on the pipeline level. These parameters will be used in the appropriate activities.

One things that I think is weird, is that there’s no date or datetime variable. String is the closest I could get to what I want to achieve. Parameters have more datatypes available, but the datetime type is missing as well.
These variables have high and low values as defaults because if for any reason there’s an issue, I can start the pipeline with the defaults. But wait, it will fail! Indeed, it will. Because if the low value is lower than the lowest lsn number, the CDC will throw angry errors. In my case, that is intended behaviour. Because I want myself to think about what I’m doing and I’m expecting the same from the other people who have the right to access this pipeline. And, if for some reason the variables fail to get the correct value, I don’t want the pipeline to continue.
This also means I have to set the variables to a value that makes sense. For this, I’m using the set variable activity.
This doesn’t do more than just set the variable to any value you want it to be. In my case, I want it to have the date of yesterday, with a time of 19:00:00 and the date of today with a time of 19:00:00. This way I should have a watertight window of 24 hours.
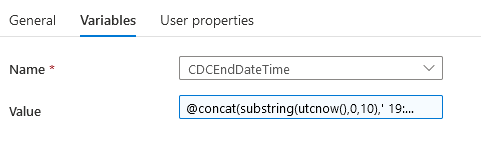
To make sure I’m getting the right date and time, I’ve had to use the trusted dynamic editor again. When I click the Set variable activity, I get the general tab and next to it is the variables tab where I can set the value. Either hardcoded or with dynamic stuff. In my case I’m trying this:

The utcnow() gives me the utc time when the pipeline runs. But all I need is the date, because the time is a fixed value. So I’m using the substring to get the first 10 positions of the utc time (yyyy-mm-dd) and with the concat I’m adding a blank followed by a time. This might or might not give me the correct timestamp. But that’s to be found out on runtime.
Variables in a SQL query
Next is to implement the variables in the query’s that are sent to the database. Remember that I’m querying the CDC tables for data? Now I’ve got to put in the values from my variables to get the lsn numbers corresponding with those datetimes.
@concat('DECLARE
@start_datetime datetime,
@end_datetime datetime,
@from_lsn binary(10),
@to_lsn binary(10)
SET @start_datetime = ''',variables('CDCStartDateTime'),'''
SET @end_datetime = ''',variables('CDCEndDateTime'),'''
/* previous code:
SET from_lsn =sys.fn_cdc_get_min_lsn(''dbo_posts'')
SET to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than or equal'' GETDATE()); */
/* new code */
SET @from_lsn = sys.fn_cdc_map_time_to_lsn(''smallest greater than or equal'', @start_datetime);
SET @to_lsn = sys.fn_cdc_map_time_to_lsn(''largest less than or equal'', @end_datetime);
SELECT count(1) changecount
FROM cdc.fn_cdc_get_all_changes_dbo_Posts(@from_lsn, @to_lsn, ''all'')')
You’ll see some weird changes in the query. This has to do with the fact that I’m using variables in the query. And those variables have to be passed into the query. The only I could get this to work is by creating a string that composes the query. So by using @concat() I can create the entire query string with the variables I’m using on runtime. When you’re doing this, be vigilant about all the single quotes in the original query, they need to become two single quotes to work. This is a highway to many errors ;). In the end, I have to agree with a lot of advice I found online stating that a stored proc to handle this for you is a more stable solution. But, it’s cool if you can get this to work. Or frustrating if you can’t.
Now both @from_lsn and @to_lsn variables are using the sys.fn_cdc_map_time_to_lsn function. This means that the datetime that is delivered from the variable is passed to this function and this function rebuilds it to the lsn corresponding with that datetime. The smallest greater than or equal and largest less than or equal operators make sure you get the right lsn for you query.
This query is usable for both the lookup activity that gets the number of records in the CDC database and the copy activity that starts moving the data.
Debugging
Let’s see if it works. First try is without data because I want to see the functions working.

Looking at all the outputs, this seems to work. All the activities in my pipeline are green, and because there are no changes, my IF activity is going to the metadata activity.
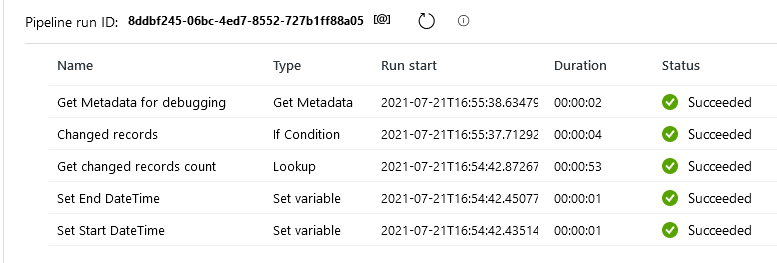
Now, after changing 64 records (I ran an update), let’s see what happens

Now, I’m copying data to my CSV. How much data did get transferred?
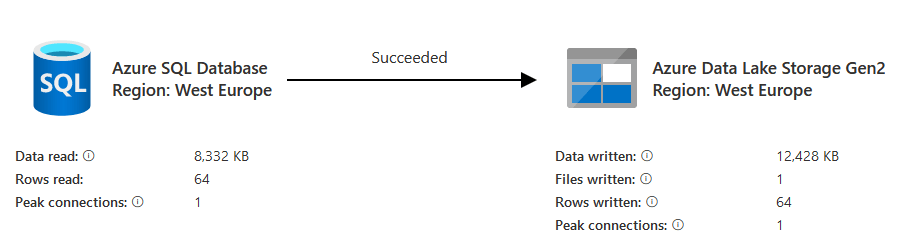
64 rows in 1 file. That’s what I was after. Happy me.
Final thoughts
Changing my fixed CDC pipeline to a dynamic one took some time. Partly because of work engagements but also because I had to find things out. Try stuff. Fail. A lot. Or, learn a lot! And that’s exactly what the main intention was of this exercise. If you want to try the same stuff, get into data factory and build your own logic and learn from it. Make your own mistakes. Or make the ones I made but didn’t show here.
My next blog on this subject will be about loading data from the parquet files to a staging layer. No more copying of data but doing some other stuff along the way as well.
Thanks for reading and leave a comment below.

One thought on “Learning ADF part 4”