
As some of you know, I’ve written a series of blog posts on Azure SQL Databases and there’s an accompanying session that I had the honour of presenting a number of times.
Now Azure keeps developing new offers and one of these went in public preview February 15th. An offer I hadn’t seen coming. You can read the introductory post here.
It’s the Azure Hyperscale Serverless option.
The docs
Scanning through the docs, you get the option to use up to 80 vcores and 240 GB memory per replica. The database scales automatically up to 100 TB. The scaling of one replica is independent of scaling of other replicas.
If you’re set on business continuity, it offers high availability configuration and fast restore speeds. On a side note, I’ve tested the restore speeds with the regular Hyperscale databases and it is indeed very fast although we had a relatively small data volume.
The database should scale as demand increases. The pricing is built of intermittent workloads. This is about the same as other serverless offerings. In my blogs on the other serverless tiers, I found out that if you’re using the database for more than 25% of the time, the provisioned offer is cheaper. So it’s essential to know your workload.
More details can be found here.
Deployment
Let’s see what the deployments show me. I’ve set the compute tier to Serverless.

I seem to have missed another announcement, even Business Critical is in serverless now. Anyway, I was writing about Hyperscale:
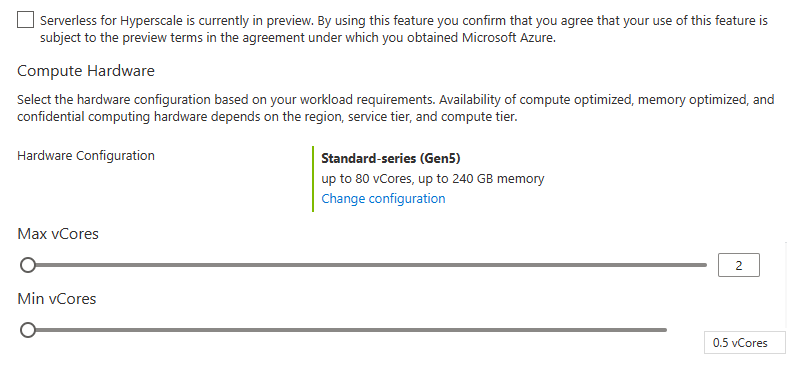
These are familiar sliders. We have the Min and Max vCores settings as seen from the General purpose serverless offering. Let’s see what the min does when sliding the max.
| Min cores | Max cores |
|---|---|
| 0.5 | 2 |
| 0.75 | 6 |
| 1 | 8 |
| 1.25 | 10 |
| 1.5 | 12 |
| 1.75 | 14 |
| 2 | 16 |
| 2.25 | 18 |
| 2.5 | 20 |
| 3 | 24 |
| 4 | 32 |
| 5 | 40 |
| 10 | 80 |
Below you see the choices for Auto-pause (not available in preview), the number of replicas and the backup storage redundancy.
My settings (let’s go big!)
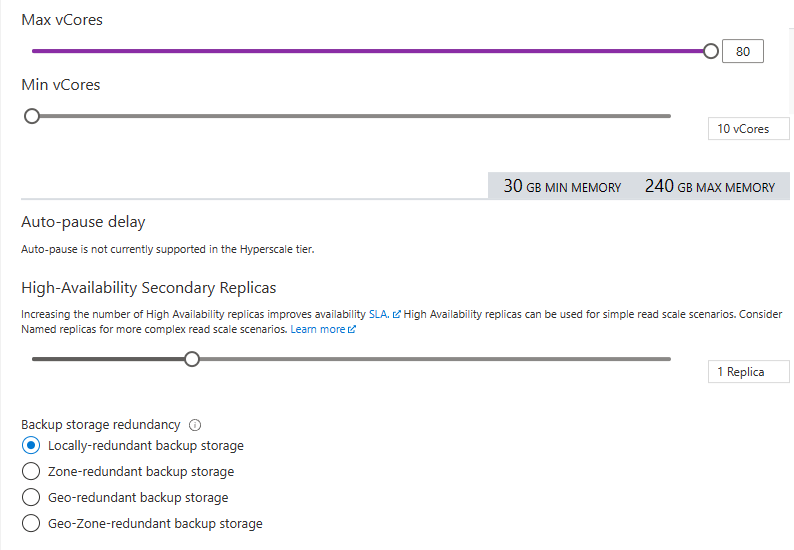
This took some time to ehm, error:
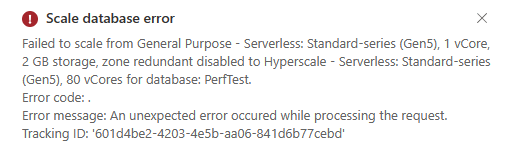
As it’s in preview, it can be expected. And, maybe my MCT subscription can’t handle this. So let’s be a bit more modest and go for 16 cores. Something we’re using this SKU in client solutions.The deployment errored again. As I was changing an existing database, I changed tactics and deployed a new one, with 16 cores.
After the deployment, I like to see what I got from the good people of Azure.
SELECT physical_memory_kb/1024/1024 AS [GB memory available],
committed_target_kb/1024/1024 AS [GB sql memory],
cpu_count AS [cpu cores],
socket_count,
numa_node_count,
cores_per_socket
max_workers_count,
scheduler_count,
scheduler_total_count,
virtual_machine_type_desc,
@@VERSION AS [sql server version]
FROM sys.dm_os_sys_info


16 cores, 40 GB of memory on 1 numa node. 20 workers max, 16 schedulers. Seems allright.
Pricing
The deployment window shows the pricing as well
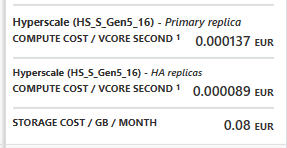
Every second I’m using this database, it will cost me 0.000137 eur per core. I’ve got 16 of them, so that makes 0.002192 per second or 0.13152 euro per minute. This transfers to 7.90 per hour, 189,38 per day and 5.681,66 per month. The provisioned edition costs about 1800 euro’s per month in the same configuration (Development). The changing point where you want to go provisioned is at 31 percent of the time or about 230 hours (10 days) in a month.
First performance test
One of the really good responses on my blog series was that I had found a fun way to load a database. Using SQL Query Stress with a command to load a table works and gives a good way to compare the different offerings, but it doesn’t show how it holds up in real life scenarios. Usually there are less concurrent processes writing many rows at once. So the suggestion came to use a TPC-H dataset and start loading the database.
Creating this dataset isn’t really hard, as long as you have enough disk space. For now I created a small set to do a first test.

5 files with order data from the TCP-H dataset, 760 MB in west europe transferred to east us in a database.
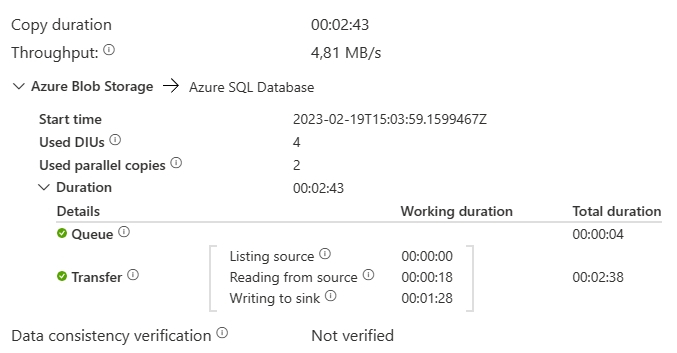
The process took a little under three minutes to load about 6.5 million rows. That’s not bad! about 40.000 records per second are loaded into the database. The target table has just the required structure, no indexes whatsoever. This really helps loading speeds of course. What happens when you add an index?
I’ve added a clustered columnstore index and restarted the load (table was dropped and recreated).
There are some small differences:
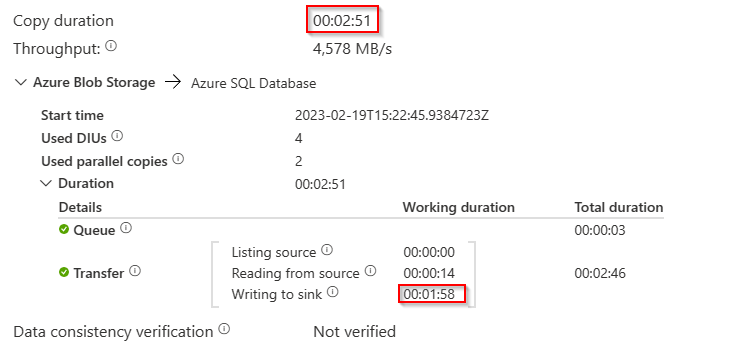
I’ve marked the two that are most important in my opinion. The copy duration went up with 8 seconds. More importantly, the process needed 30 seconds more to write to the sink.
Database usage
Let’s look at the data as presented in the Azure portal
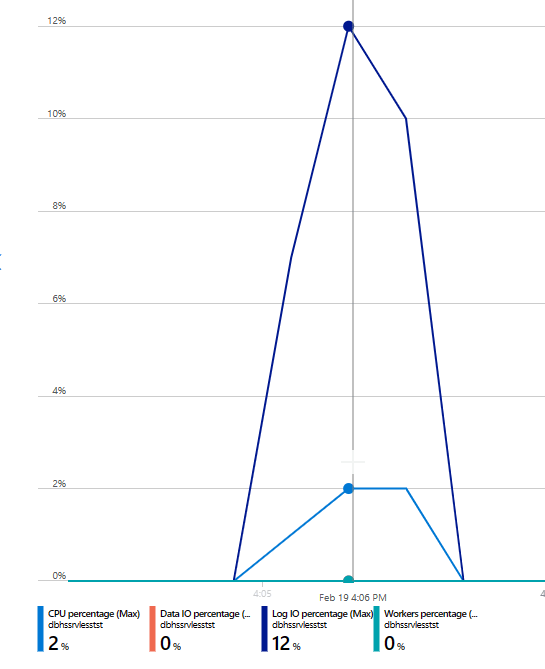
Let’s say my processors were not impressed with the load. The log had to wake up but wasn’t extremely busy as well.
Concluding
Well, after a first sunday afternoon playing around with this offer, it feels like a fun one. It needs a bit more testing and comparison against the provisioned tier to see how it’s holding up. For max speed, my datafiles, data factory and database should be in the same region. That will come in a next blog.
Thanks for reading!

One thought on “Azure Hyperscale Serverless, first impressions”